This article also has an English version .
本系列文章主要记录我在尝试用 Rust 实现一个 Hypervisor 的过程。目录:
用 Rust 实现极简 VMM - 基础 用 Rust 实现极简 VMM - 模式切换 用 Rust 实现极简 VMM - 运行真实的 Linux Kernel 用 Rust 实现极简 VMM - 实现 Virtio 设备
本文是系列的第四篇,会从零实现 Virtio Queue,并使用 TAP 作为 backend 实现 virtio-net 设备;为了把这些组件更好地组装起来,还会做一些组件,类似 Bus、EventLoop。
下一篇可能会支持 PCI 设备和 VF 设备直通(如果我有时间的话)。
之前的三篇文章都完成于 2022 年下半年,本章节以及对应的实验代码一直以草稿的形式闲置,直到最近(现在是 2024 年)我想要将这个坑填上,于是抽了几个周末较为细致地补充了一些代码,并完成本文。
Virtio 简介 Virtio 主要参考官方 1.1 文档(1.0 版本也可以):https://docs.oasis-open.org/virtio/virtio/v1.1/csprd01/virtio-v1.1-csprd01.html 。
在全虚拟化模式下,在 guest 试图 IO 时,这些对设备的操作会触发 VM EXIT,每次 VM EXIT 会中断 VM 正在执行的上下文,带来非常大的切换开销。
Virtio 是一个协议,用于虚拟化一些设备。当 host 和 guest 都遵从这个协议时,可以利用共享内存承载 IO 请求和响应,降低切换次数提升 IO 性能。因为它需要 guest 的配合才能工作,所以称为半虚拟化。
除了通过共享内存优化性能外,也有其他高性能 IO 方案,例如由硬件设备自身直接支持虚拟化(SR-IOV),可以将单个硬件设备虚拟化为多个 Virtual Function,这样我们就可以将单个 Function 交由 VM 独享(此时需要依赖 IOMMU 来完成地址转换)。
Virtio 的实现在 Guest 中通常由内核态的驱动支持,在 Host 中通常由 VMM 实现者负责实现。有时为了达到更好的性能,Host 中的实现也可以放到内核中做(vhost,这样可以节省 Host 内核态与用户态切换开销,另外也可以利用在用户态无法使用的硬件指令来优化)或独立进程(vhost-user,可以将例如虚拟网络等与 VMM 无关的逻辑从 VMM 代码中剥离,并精细化控制进程的权限),甚至可以直接由硬件支持(vDPA)。
Windows 和 Linux 都有 virtio 对应驱动(Linux 下有 virtio-net, virtio-blk 等),所以若 VMM 支持 virtio,当其在 VM 中运行时可以获得较好的 IO 性能。
一个 Virtio 设备包含五个部分:
Device Status Field Feature Bits Notifications Device Configuration Space Virtqueues
顾名思义,设备状态域用于设备的状态表示;特性位用于 feature 协商;配置空间通常用于那些不常改动,或初始化时的参数(比如对于 Balloon 设备 page 的个数),或设备特有的信息;virtqueue 用于数据传输(一个设备可以有零个或多个 virtqueue);notifications 包含两大类通知,一种是 ring 的通知(available buffer 和 used buffer),另一种是 config space 的通知。
如何双向通知?Guest 通知 Host 通常称为 kick,一般使用 KVM 提供了 ioeventfd 能力,当 Guest 向特定 MMIO/PIO 地址写特定值时,会触发 EPT misconfiguration 异常,KVM 会负责处理该异常并将其转换为写 eventfd 来通知 Host(当然也可以利用 VM_EXIT 实现,但相对性能较差);Host 通知 Guest 前面已经讲过,是注入中断实现的,可以利用 irqfd 控制。
数据流 握手 通常 Virtio 可以基于 MMIO 或 PCI 工作(还有一种基于 channel io 的,用于 S390 平台)。PCI 接口支持设备热拔插,也有方便直接映射物理设备到 VM 内,但是对于 virtio 设备来说,实现 PCI 会大幅度增加实现复杂度(https://lwn.net/Articles/812055/ 有一个参考数据,qemu 中 virtio-MMIO 实现涉及单个文件的 421 行代码,但 virtio-PCI 涉及 24 个文件中的 8952 行,是 virtio-MMIO 的 20 倍多),而越复杂可能的攻击面就更大,同时也会拖慢驱动速度。
由于我们只想实现基础可用的 VMM,没有太多物理设备映射需求,所以我们这里会使用 MMIO。
设备需要 Guest 发现并协商握手成功才能使用。设备初始化按照这个顺序:
The driver MUST follow this sequence to initialize a device:
Reset the device.
Set the ACKNOWLEDGE status bit: the guest OS has notice the device.
Set the DRIVER status bit: the guest OS knows how to drive the device.
Read device feature bits, and write the subset of feature bits understood by the OS and driver to the device. During this step the driver MAY read (but MUST NOT write) the device-specific configuration fields to check that it can support the device before accepting it.
Set the FEATURES_OK status bit. The driver MUST NOT accept new feature bits after this step.
Re-read device status to ensure the FEATURES_OK bit is still set: otherwise, the device does not support our subset of features and the device is unusable.
Perform device-specific setup, including discovery of virtqueues for the device, optional per-bus setup, reading and possibly writing the device’s virtio configuration space, and population of virtqueues.
Set the DRIVER_OK status bit. At this point the device is “live”.
If any of these steps go irrecoverably wrong, the driver SHOULD set the FAILED status bit to indicate that it has given up on the device (it can reset the device later to restart if desired). The driver MUST NOT continue initialization in that case.
设备初始化和状态变更由 Guest/Driver 侧发起,所以在 VMM/Device 中我们只要处理对应事件即可。
在 PCI 协议下可以利用其机制实现设备发现,MMIO 下没有对应机制,可以通过向 linux 启动 cmdline 插入设备描述来使其发现设备。
例如,插入 virtio_mmio.device=4K@0xd0000000:5 表示有一个基于 MMIO 的 virtio 设备,其 MMIO 地址段起始位置是 0xd0000000,长度为 4K,irq 是 5。
Device 会通过读写设备 MMIO 地址段的特定偏移的地址来执行约定的动作。例如,Offset = 0 只允许读取,且需要返回 0x74726976 (”virt” 的 ascii 小端表示);Offset = 0x10 只读,Device 需要返回其支持的 feature;Offset = 0x14 只写,向 Device 写入其选择的 feature。
Guest 发现设备后,即可选择合适的时机执行初始化逻辑。状态变更顺序在前面的文档里已经说的很清楚了,不再赘述。
设备需要支持这些读写,但每个设备对这些读写的处理都是十分类似的,所以我们可以抽象出一层 Wrapper 结构,这里可以命名为 MMIOTransport,它用于包装具体设备实现,并自己存储一些握手需要的信息(例如 queue_select),将 MMIO 读写操作转换为对自身 field 和内层设备操作。具体的设备实现也需要做一定抽象,暴露通用的操作接口给 MMIOTransport 调用。
通信 当握手时:
所有读写均通过写 MMIO 触发 VM_EXIT 后由 vCPU 模拟线程处理;
当握手完成后,Guest 想发送一段内容时:
[Guest] 从 Used Ring 中取 Descriptor Chain,并向其指代的 buffer 写入数据;
[Guest] 之后将该 Descriptor index(如果是多个 Descriptor 组成的链,只需要取第一个的 index)写入 Available Ring,并更新 Available Ring 上的 Index;
[Guest] 需要通知 Host 消费,这里会通过 PCI 或写 MMIO 的形式触发,并由 KVM 感知;
[Host Kernel] 当 KVM 感知后,会通知预注册好的对应 VMM 侧 IoEventFd;
[Host User] VMM 收到通知后会消费 Available Ring,得到 Descriptor Table Index,取出对应 Descriptor Chain 并处理 buffer 内的数据(例如将其转发到网卡),在处理完毕后将 Descriptor Table Index 放回 Used Ring;
[Host User] 写入 Used Ring 后需要通过 IrqFd 通知 Guest 处理;
当 Host 想向 Guest 发送一段数据时:
[Host User] 从 Available Ring 取出 Descriptor Chain,并向其指代的 buffer 写入数据;
[Host User] 之后将该 Descriptor index(如果是多个 Descriptor 组成的链,只需要取第一个的 index)和数据总长度写入 Used Ring,并更新 Used Ring 上的 Index;
[Host User] 需要通知 Guest 消费,这里会通过 IrqFd 通知;
[Host Kernel] 在 VMM 写入 eventfd 后,KVM 向虚拟机注入与之绑定的中断;
[Guest] 收到中断后,Guest 驱动程序会消费 Used Ring,取得 Descriptor Table Index 和数据长度,读出想要的数据;
[Guest] 读取完毕后需要将 Descriptor Table Index 放回 Available Ring;
实现 要实现 vitrio 设备,需要实现这么几个部分:
virtio queue:用于单向通信(当一个 device 需要双向通信时,可以使用两个 queue)
mmio/pci transport:用于完成 feature 协商、状态获取和变更、配置读取和写入等
virtio device:这个是具体的 virtio 设备实现,例如 virtio-net、virtio-blk 等
Virtio Queue Virtioqueue 是 virtio 的灵魂所在,它约定了对共享内存的使用方式。virtio 当前主要有三个版本(1.0、1.1 和 1.2,更之前的版本称为 legacy),1.1 及后续版本中甚至区分了 Split 和 Packed 两种,但简便起见我们只讨论 Split 版本。
一个 virtqueue 由这三部分组成:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 struct VirtualQueue { struct Buffers [QueueSize] { uint64_t Address; uint32_t Length; uint16_t Flags; uint16_t Next; } struct Available { uint16_t Flags; uint16_t Index; uint16_t [QueueSize] Ring; uint16_t EventIndex; } uint8_t[] Padding; struct Used { uint16_t Flags; uint16_t Index; struct Ring [QueueSize] { uint32_t Index; uint32_t Length; } uint16_t AvailEvent; } }
Descriptor Table 负责存储多个 Descriptor;通过 index 即可读出对应 Descriptor;Descriptor 中包含 buffer 指针(GPA)和长度,以及链起来的下一个 Descriptor index。
Available Ring 负责存储多个 Descriptor Index 和 Ring Index(指示其下次写入位置)。Guest 只写 Available Ring,Host 只读。
Used Ring 负责存储多个 Descriptor Index 以及该 Descriptor 对应的已写入数据总长度,和 Ring Index(指示其下次写入位置)。Guest 只读 Used Ring,Host 只写。
Descriptor Chain 如何描述 Descriptor Chain?Descriptor 内存储了 Next Descriptor index,所以我们只要额外存储 Descriptor Table 地址,以及内存地址映射就可以让这个结构能够自己读取出下一个 Descriptor。
内存地址映射存储为泛型 M,其既可以是有所有权的类型,也可以是引用类型。我们使用 M 时通常有三种方式:一种是临时使用,这种传递 &M 并约束 M: GuestMemory 即可(会 auto deref);另一种是消耗 M 构造持有 M 的结构,并需要操作 M,类似 Queue::pop<M>,这时传递 M 并约束 M: Deref<Target = impl GuestMemory>(手动 deref);还有一种是在不消耗 M 的情况下构造持有 M 的结构,,例如 DescriptorChain::<M>::next 这时相比前一种用法,需要额外约束 M: Clone。需要注意的是,使用时务必留意 M 的类型,如果 M 对应了一个所有权类型,那么 Clone 的开销可能比较大,需要关注这是不是符合预期的。如果期望 M 一定是引用类型或其他可以廉价拷贝的类型,可以将前面的 Clone 约束改为 Copy 约束。
另外存储 queue size 以检查 index 是否合法,并存储当前 index 以供读取。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 pub struct DescriptorChain <M> { mem: M, desc_table: GuestAddress, queue_size: u16 , pub index: u16 , pub addr: u64 , pub len: u32 , pub flags: u16 , pub next: u16 , } impl <M: Deref<Target = impl GuestMemory >> DescriptorChain<M> { pub fn new (mem: M, desc_table: GuestAddress, queue_size: u16 , index: u16 ) -> Result <Self , ()> { if index >= queue_size { error!("invalid index {index}, queue size: {queue_size}" ); return Err (()); } Ok (Self ::new_unchecked (mem, desc_table, queue_size, index)) } #[inline(always)] pub fn new_unchecked (mem: M, desc_table: GuestAddress, queue_size: u16 , index: u16 ) -> Self { #[repr(C)] #[derive(Default, Clone, Copy)] struct Descriptor { addr: u64 , len: u32 , flags: u16 , next: u16 , } unsafe impl ByteValued for Descriptor {} let addr = desc_table.unchecked_add ((index as u64 ) << 4 ); let desc = mem.read_obj::<Descriptor>(addr).unwrap (); Self { mem, desc_table, queue_size, index, addr: desc.addr, len: desc.len, flags: desc.flags, next: desc.next, } } pub fn next (&self ) -> Option <Result <Self , ()>> where M: Clone , { const VIRTQ_DESC_F_NEXT: u16 = 0x1 ; if self .flags & VIRTQ_DESC_F_NEXT != 0 { Some (Self ::new ( self .mem.clone (), self .desc_table, self .queue_size, self .next, )) } else { None } } #[inline] pub const fn is_write_only (&self ) -> bool { const VIRTQ_DESC_F_WRITE: u16 = 0x2 ; self .flags & VIRTQ_DESC_F_WRITE != 0 } #[allow(unused)] pub fn write_at (self , mut offset: usize , mut data: &[u8 ]) -> io::Result <()> where M: Clone , { if data.is_empty () { return Ok (()); } let mut next_desc = Some (self ); while let Some (desc) = next_desc { let skip = offset.min (desc.len as usize ); offset -= skip; if offset == 0 { let to_copy = data.len ().min (desc.len as usize - skip); desc.mem .write_slice (&data[..to_copy], GuestAddress (desc.addr + skip as u64 )) .map_err (|_| io::Error::new (io::ErrorKind::Other, "Failed to write slice" ))?; data = &data[to_copy..]; if data.is_empty () { return Ok (()); } } next_desc = desc.next ().transpose ().map_err (|_| { io::Error::new (io::ErrorKind::Other, "Failed to get next descriptor" ) })?; } Err (io::Error::new ( io::ErrorKind::Other, "Failed to write slice" , )) } }
这样我们就可以借助 DescriptorChain 结构解决加载下一个 Descriptor 的问题。之后我们需要为 Queue 实现 push/pop 方法来读写 DescriptorChain。
Queue 定义 我们需要先定义出 Queue struct。Queue 需要存储哪些信息?
Queue 的内存由 Guest 管理,所以 Device 侧实现只需要记录这三项的内存地址;
为了存储握手时设置 per-Queue 的信息,也需要在 Queue 中存储相应的字段,包括 size 和 ready;
记录当前读写 index(next_avail, next_used),以及当前 batch 写入次数(num_added);
存储握手时通过初始值或 feature 协商获得的信息,包括 max_size 和 noti_suppres(noti_suppres 即表示 VIRTIO_F_EVENT_IDX feature);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 pub struct Queue { pub desc_table: GuestAddress, pub avail_ring: GuestAddress, pub used_ring: GuestAddress, pub size: u16 , pub ready: bool , pub next_avail: Wrapping<u16 >, pub next_used: Wrapping<u16 >, pub num_added: Wrapping<u16 >, pub max_size: u16 , pub noti_suppres: bool , } impl Queue { pub const fn new (max_size: u16 ) -> Self { Self { max_size, size: 0 , ready: false , desc_table: GuestAddress (0 ), avail_ring: GuestAddress (0 ), used_ring: GuestAddress (0 ), next_avail: Wrapping (0 ), next_used: Wrapping (0 ), noti_suppres: false , num_added: Wrapping (0 ), } } }
Interrupt Suppression 有必要介绍一下 VIRTIO_F_EVENT_IDX 这个 feature。
在不支持该 feature 的实现下,每次写入消息后(可以是多条),都需要通知对端消费(毕竟对端无法感知本地写了内存,所有的基于共享内存的通信都需要忙等或基于某种通知机制)。但通知的代价是昂贵的,为了尽量减少通知次数,同时又不引入延迟,这个 feature 被设计出来。
当该 feature 被成功协商后,对于 device 来讲,只有当对端完成 index 为 UsedRing.AvailEvent 的 AvailableRing 写入时,才会得到通知;只有当本地写入 index 为 AvailableRing.EventIndex 的 UsedRing 写入时,才通知对端(这句里的变量命名对应前面的 C 语言定义)。
在开启该 feature 后,需要特别关注内存可见性问题,可以通过插入合理的内存屏障确保一致性。
并且,一旦开启 VIRTIO_F_EVENT_IDX,那么就意味着需要一次消费完所有事件(或者通过内部触发 callback 的形式后续消费)。这是因为对端不会再有通知过来,类似于处理 epoll ET 时的实现——要么一口气消费完,要么记录 readiness 并由内部产生的信号触发 fd 消费。
Queue Pop 实现 pop 包含两个任务:
感知有消息可消费
从 Queue 里取出消息
任务 2 非常简单,只需要读区 Descriptor Table 中的 next_avail index 对应数据即可。由于其必须确保元素存在,所以我们将其命名为 pop_unchecked。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 impl Queue { #[inline] fn pop_unchecked <M: Deref<Target = impl GuestMemory >>( &mut self , mem: M, ) -> Result <DescriptorChain<M>, ()> { let addr = self .avail_ring .unchecked_add ((((self .next_avail.0 % self .size) as u64 ) << 1 ) + 4 ); let desc_index = mem.read_obj::<u16 >(addr).unwrap (); let desc_chain = DescriptorChain::new (mem, self .desc_table, self .size, desc_index); if desc_chain.is_ok () { self .next_avail += 1 ; } else { error!("pop_unchecked failed because invalid desc index" ); } desc_chain } }
那么如何判定是否有消息可消费呢?这很简单,直接判定 AvailableRing 的 Index 是否大于 next_avail 不就可以了吗?我们实现一个读取 AvailableRing Index 的函数,并基于这个实现 len 函数:
1 2 3 4 5 6 7 8 9 10 11 12 impl Queue { #[inline(always)] fn avail_idx <M: GuestMemory>(&self , mem: &M) -> Wrapping<u16 > { let addr = self .avail_ring.unchecked_add (2 ); Wrapping (mem.read_obj::<u16 >(addr).unwrap ()) } #[inline(always)] fn len <M: GuestMemory>(&self , mem: &M) -> u16 { (self .avail_idx (mem) - self .next_avail).0 } }
当 .len() > 0 则 pop_unchecked,这个实现对于未协商 VIRTIO_F_EVENT_IDX 的 case 是 work 的。但当该 feature 开启时,则需要:
尝试获取 len, len>0 则直接读取并返回
写入 UsedRing.AvailEvent,即告诉 Guest 有新数据时通知 Device
再次尝试读取 len
为什么需要再次尝试呢?前面说到,当 VIRTIO_F_EVENT_IDX 开启时,需要一次性消费完所有消息,如果生产端认为不需要触发,而消费端又中途停止,则会卡住,消息无人处理。
我们将 Host Device 读取 len 记作事件 1,Host Device 更新 UsedRing.AvailEvent 记做事件 2;将 Guest Driver 更新 len 记作事件 A,Guest Driver 读取 UsedRing.AvailEvent 记做事件 B。那么,1、2是有顺序保证的,A、B是有顺序保证的,这样就有这么几种顺序组合:
A12B/A1B2/AB12:都是先更新 len 再读取 len,所以不会漏消息;
1A2B/12AB:Device 先读 len 发现无消息认为结束,但 Driver 成功读到了最新的 AvailEvent,所以虽然消费停止,但仍旧会被下一次通知正确触发,所以不会漏消息;
1AB2:这种 case 下,Device 认为无消息可消费,但 Guest 稍后又产生一个新消息,并读取 AvailEvent(发现是旧值),最后 Device 再更新 AvailEvent 并退出处理流程。显然 Device 既没有消费完消息,又没有确保正确设置 AvailEvent,此时退出就会导致漏消息。
怎么解决这个问题呢?就是在更新完 AvailEvent 后再次尝试读消息。这样就能在 case3 发生时继续消费循环。
为了获取到最新的 len,我们在 Pop 时先加一个 Acquire fence 保证对写者 Release fense 前写入内存的可见性;在写入 AvailEvent 后,需要使其对读者 Acquire fence 后可见,所以需要 Release fense,而同时我们仍旧需要得到当前最新的 len,于是我们使用一个 AcqRel fence。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 impl Queue { #[inline] pub fn pop <M: Deref<Target = impl GuestMemory >>( &mut self , mem: M, ) -> Result <Option <DescriptorChain<M>>, ()> { macro_rules! try_pop { () => { if self .len (mem.deref ()) != 0 { return self .pop_unchecked (mem).map (Option ::Some ); } }; } fence (Ordering::Acquire); try_pop!(); if self .noti_suppres { let avail_event_addr = self .used_ring.unchecked_add (((self .size as u64 ) << 3 ) + 4 ); mem.write_obj (self .next_avail.0 , avail_event_addr).unwrap (); fence (Ordering::AcqRel); try_pop!(); } Ok (None ) } }
Queue Push Device 侧 Queue Push 只需要将消息写入 Used Ring。由于 Descriptor Index 一定是从 AvailableRing 取出的,而 AvailableRing、Used Ring、Descriptor Table 大小一致,所以此时一定是有空间可以写入的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 impl Queue { #[inline] pub fn push <M: GuestMemory>(&mut self , mem: &M, desc_index: u16 , len: u32 ) { #[repr(C)] #[derive(Default, Clone, Copy)] struct UsedElem { id: u32 , len: u32 , } unsafe impl ByteValued for UsedElem {} let addr = self .used_ring .unchecked_add ((((self .next_used.0 % self .size) as u64 ) << 3 ) + 4 ); let id = desc_index as u32 ; mem.write_obj (UsedElem { id, len }, addr).unwrap (); self .num_added += 1 ; self .next_used += 1 ; fence (Ordering::Release); mem.write_obj (self .next_used.0 , self .used_ring.unchecked_add (2 )) .unwrap (); } }
这部分实现并不困难,直接计算地址并向其写入 C 内存布局的数据即可。需要注意的是,必须确保数据先写入完毕,才能更新 Ring Index:所以这里需要在更新 Ring Index 前使用 Release fence。
在数据写完并更新 Ring Index 后,需要通知对端。同样需要考虑 VIRTIO_F_EVENT_IDX feature 的开启状态:
在 VIRTIO_F_EVENT_IDX 不开启时,批量写入完毕一定要通知对端。
这里有个例外,此时当 flag 为 1 时不通知对端(flag 取值只能为 0 或 1)。
在 VIRTIO_F_EVENT_IDX 开启时,只有写入了特定 Index 的数据后才需要通知。
所以这里可以实现一个 prepare_notify 函数,当返回 true 时由设备负责 notify。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 impl Queue { #[inline] pub fn prepare_notify <M: GuestMemory>(&mut self , mem: &M) -> bool { if !self .noti_suppres { let flags = mem.read_obj::<u16 >(self .avail_ring).unwrap (); return flags == 0 ; } fence (Ordering::AcqRel); let used_event_addr = self .avail_ring.unchecked_add (((self .size as u64 ) << 1 ) + 4 ); let used_event = Wrapping (mem.read_obj::<u16 >(used_event_addr).unwrap ()); let num_added = self .num_added; self .num_added = Wrapping (0 ); self .next_used - used_event - Wrapping (1 ) < num_added } }
由于需要保证先前的内存写入与 Ring Index 更新的可见性,又需要保证后面读 used_event 的可见性,所以这里使用 AcqRel fence。最后计算是否需要 notify 的表达式很巧妙,参考了 kernel driver 侧的实现,它低成本地正确处理了 wrap 时的情况。
Queue Validate 由于 Queue 的读写都是热路径,并且 Queue 内两个 Ring 和 Descriptor Table 的 size 与 addr 在握手成功后都是不变的,所以为了提高性能,可以提前对其做合法性校验,并在后续操作中假定其内存布局与长度合法。
根据文档 ,我们需要校验三个内存地址的 layout:
Descriptor Table 需要 16 byte 对齐,其大小为 16*(Queue Size)
Available Ring 需要 2 byte 对齐,其大小为 6 + 2*(Queue Size)
Used Ring 需要 4 byte 对齐,其大小为 6 + 8*(Queue Size)
并且,由于 MMIO write 时直接操作 size,所以我们需要校验其写入的 size 合法性:
size 必须是 power of 2
size 最大值是 32768
最后,我们需要校验设备状态为 ready(通过 offset = 0x044 读写)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 impl Queue { pub fn is_valid <M: GuestMemory>(&self , mem: &M) -> bool { if !self .ready { return false ; } if self .size > self .max_size { return false ; } if self .size == 0 || self .size & (self .size - 1 ) != 0 || self .size > 32768 { return false ; } if self .desc_table.raw_value () & 0xf != 0 { return false ; } if self .avail_ring.raw_value () & 0x1 != 0 { return false ; } if self .used_ring.raw_value () & 0x3 != 0 { return false ; } if mem .get_slice (self .desc_table, (self .size as usize ) << 4 ) .is_err () { return false ; } if mem .get_slice (self .avail_ring, ((self .size as usize ) << 1 ) + 6 ) .is_err () { return false ; } if mem .get_slice (self .avail_ring, ((self .size as usize ) << 3 ) + 6 ) .is_err () { return false ; } true } }
MMIO Transport 所有 virtio 设备都需要 feature 协商、状态和 config space 操作等,并且除了 MMIO 外,还可能需要支持 PCI(操作语义大致相同)。一个良好的设计是将对 virtio 设备的访问抽象为 trait,并写一个 Adaptor (即 Transport)来将其对接到 MMIO 访问或 PCI 上。
对 virtio 设备的接口设计取决于 transport 的访问。MMIOTransport 对具体 MMIO offset 上读写的响应需要参考文档 4.2.2 MMIO Device Register Layout 实现。
这里我直接 copy 了 firecracker 的接口(非常小地改了一点):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 pub trait VirtioDevice : Send { fn avail_features (&self ) -> u64 ; fn acked_features (&self ) -> u64 ; fn set_acked_features (&mut self , acked_features: u64 ); fn has_feature (&self , feature: u64 ) -> bool { (self .acked_features () & feature) != 0 } fn device_type (&self ) -> u32 ; fn queues (&self ) -> &[Queue]; fn queues_mut (&mut self ) -> &mut [Queue]; fn queue_events (&self ) -> &[EventFd]; fn interrupt_trigger (&self ) -> &IrqTrigger; fn interrupt_status (&self ) -> Arc<AtomicU32> { Arc::clone (&self .interrupt_trigger ().irq_status) } fn avail_features_by_page (&self , page: u32 ) -> u32 { let avail_features = self .avail_features (); match page { 0 => (avail_features & 0xFFFFFFFF ) as u32 , 1 => (avail_features >> 32 ) as u32 , _ => 0u32 , } } fn ack_features_by_page (&mut self , page: u32 , value: u32 ) { let mut v = match page { 0 => u64 ::from (value), 1 => u64 ::from (value) << 32 , _ => 0u64 , }; let avail_features = self .avail_features (); let unrequested_features = v & !avail_features; if unrequested_features != 0 { v &= !unrequested_features; } self .set_acked_features (self .acked_features () | v); } fn read_config (&self , offset: u32 , data: &mut [u8 ]); fn write_config (&mut self , offset: u32 , data: &[u8 ]); fn activate (&mut self , mem: GuestMemoryMmap) -> io::Result <()>; fn is_activated (&self ) -> bool ; fn reset (&mut self ) -> Option <(EventFd, Vec <EventFd>)> { None } }
MMIOTransport 需要持有具体设备以便以 VirtioDevice 接口对其访问;另外需要记录一些 feature 协商和握手时的必要状态。这里的实现也需要按照前文提到的文档进行。
这里我依旧是 copy 了 firecracker 的代码(非常小地改了一点):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 const MMIO_MAGIC_VALUE: u32 = 0x7472_6976 ;const MMIO_VERSION: u32 = 2 ;const VENDOR_ID: u32 = 0 ;pub struct MMIOTransport { device: Arc<Mutex<dyn VirtioDevice>>, features_select: u32 , acked_features_select: u32 , queue_select: u32 , device_status: u32 , interrupt_status: Arc<AtomicU32>, config_generation: Wrapping<u32 >, mem: GuestMemoryMmap, } impl MMIOTransport { pub fn new (device: Arc<Mutex<dyn VirtioDevice>>, mem: GuestMemoryMmap) -> Self { let interrupt_status = device.lock ().unwrap ().interrupt_status (); Self { device, features_select: 0 , acked_features_select: 0 , queue_select: 0 , device_status: 0 , interrupt_status, config_generation: Wrapping (0 ), mem, } } } mod device_status { pub const INIT: u32 = 0 ; pub const ACKNOWLEDGE: u32 = 1 ; pub const DRIVER: u32 = 2 ; pub const FAILED: u32 = 128 ; pub const FEATURES_OK: u32 = 8 ; pub const DRIVER_OK: u32 = 4 ; pub const DEVICE_NEEDS_RESET: u32 = 64 ; } impl MMIOTransport { #[inline] fn with_queue <F: FnOnce (&Queue) -> O, O>(&self , f: F) -> Option <O> { self .device .lock () .unwrap () .queues () .get (self .queue_select as usize ) .map (f) } #[inline] fn with_queue_mut <F: FnOnce (&mut Queue) -> O, O>(&mut self , f: F) -> Option <O> { self .device .lock () .unwrap () .queues_mut () .get_mut (self .queue_select as usize ) .map (f) } #[inline] const fn check_device_status (&self , set: u32 , clr: u32 ) -> bool { self .device_status & (set | clr) == set } #[inline] fn update_queue_field <F: FnOnce (&mut Queue)>(&mut self , f: F) { if self .check_device_status ( device_status::FEATURES_OK, device_status::DRIVER_OK | device_status::FAILED, ) { self .with_queue_mut (f); } } fn set_device_status (&mut self , status: u32 ) { use device_status::*; match !self .device_status & status { ACKNOWLEDGE if self .device_status == INIT => { self .device_status = status; } DRIVER if self .device_status == ACKNOWLEDGE => { self .device_status = status; } FEATURES_OK if self .device_status == (ACKNOWLEDGE | DRIVER) => { self .device_status = status; } DRIVER_OK if self .device_status == (ACKNOWLEDGE | DRIVER | FEATURES_OK) => { self .device_status = status; let mut locked_device = self .device.lock ().unwrap (); let device_activated = locked_device.is_activated (); if !device_activated && locked_device .queues () .iter () .all (|q: &Queue| q.is_valid (&self .mem)) { let activate_result = locked_device.activate (self .mem.clone ()); if activate_result.is_err () { self .device_status |= DEVICE_NEEDS_RESET; let _ = locked_device.interrupt_trigger ().trigger (IrqType::Config); } } } _ if (status & FAILED) != 0 => { self .device_status |= FAILED; } _ if status == 0 => { let mut locked_device = self .device.lock ().unwrap (); if locked_device.is_activated () { let mut device_status = self .device_status; let reset_result = locked_device.reset (); match reset_result { Some ((_interrupt_evt, mut _queue_evts)) => {} None => { device_status |= FAILED; } } self .device_status = device_status; } if self .device_status & FAILED == 0 { self .features_select = 0 ; self .acked_features_select = 0 ; self .queue_select = 0 ; self .interrupt_status.store (0 , Ordering::SeqCst); self .device_status = device_status::INIT; for queue in locked_device.queues_mut () { *queue = Queue::new (queue.max_size); } } } _ => {} } } pub fn bus_read (&mut self , offset: u64 , data: &mut [u8 ]) { match offset { 0x00 ..=0xff if data.len () == 4 => { let v = match offset { 0x0 => MMIO_MAGIC_VALUE, 0x04 => MMIO_VERSION, 0x08 => self .device.lock ().unwrap ().device_type (), 0x0c => VENDOR_ID, 0x10 => { let mut features = self .device .lock () .unwrap () .avail_features_by_page (self .features_select); if self .features_select == 1 { features |= 0x1 ; } features } 0x34 => self .with_queue (|q| u32 ::from (q.max_size)).unwrap_or (0 ), 0x44 => self .with_queue (|q| u32 ::from (q.ready)).unwrap_or (0 ), 0x60 => self .interrupt_status.load (Ordering::SeqCst), 0x70 => self .device_status, 0xfc => self .config_generation.0 , _ => { return ; } }; data.copy_from_slice (v.to_le_bytes ().as_slice ()); } 0x100 ..=0xfff => self .device .lock () .unwrap () .read_config ((offset - 0x100 ) as u32 , data), _ => {} } } pub fn bus_write (&mut self , offset: u64 , data: &[u8 ]) { fn hi (v: &mut GuestAddress, x: u32 ) { *v = (*v & 0xffff_ffff ) | (u64 ::from (x) << 32 ) } fn lo (v: &mut GuestAddress, x: u32 ) { *v = (*v & !0xffff_ffff ) | u64 ::from (x) } match offset { 0x00 ..=0xff if data.len () == 4 => { let mut buf : [u8 ; 4 ] = [0 ; 4 ]; buf.copy_from_slice (data); let v = u32 ::from_le_bytes (buf); match offset { 0x14 => self .features_select = v, 0x20 => { if self .check_device_status ( device_status::DRIVER, device_status::FEATURES_OK | device_status::FAILED | device_status::DEVICE_NEEDS_RESET, ) { self .device .lock () .unwrap () .ack_features_by_page (self .acked_features_select, v); } } 0x24 => self .acked_features_select = v, 0x30 => self .queue_select = v, 0x38 => self .update_queue_field (|q| q.size = (v & 0xffff ) as u16 ), 0x44 => self .update_queue_field (|q| q.ready = v == 1 ), 0x64 => { if self .check_device_status (device_status::DRIVER_OK, 0 ) { self .interrupt_status.fetch_and (!v, Ordering::SeqCst); } } 0x70 => self .set_device_status (v), 0x80 => self .update_queue_field (|q| lo (&mut q.desc_table, v)), 0x84 => self .update_queue_field (|q| hi (&mut q.desc_table, v)), 0x90 => self .update_queue_field (|q| lo (&mut q.avail_ring, v)), 0x94 => self .update_queue_field (|q| hi (&mut q.avail_ring, v)), 0xa0 => self .update_queue_field (|q| lo (&mut q.used_ring, v)), 0xa4 => self .update_queue_field (|q| hi (&mut q.used_ring, v)), _ => {} } } 0x100 ..=0xfff => { if self .check_device_status ( device_status::DRIVER, device_status::FAILED | device_status::DEVICE_NEEDS_RESET, ) { self .device .lock () .unwrap () .write_config ((offset - 0x100 ) as u32 , data); self .config_generation += 1 ; } } _ => {} } } }
Virtio-net 实现 virtio-net 包含两条 virtio queue,用于双向通信。
我们要如何处理 virtio-net 读写的数据包呢?virtio-net 面向的是二层数据包,一个实现是创建一个 TAP 设备(也工作在二层),之后将 virtio-net 的 tx 和 rx 与该 TAP 设备对接。
如何利用 TAP 设备使 VM 可以访问宿主机之外的网络呢?
一个办法是为 TAP 分配一个地址和网段,并设定 VM 的 ip 为另一个该网段地址;之后通过 iptables 完成 nat,并由 host 内核转发。
另一个办法是将 TAP 与出口网卡(例如 eth0)桥接,并在 VM 内部配置同段 ip。
定义 Net 结构(包含 TAP 设备、两个 Queue 以及各自的 ioeventfd、设备绑定的 irqfd、features 与状态):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 const NET_NUM_QUEUES: usize = 2 ;const VIRTIO_TYPE_NET: u32 = 1 ;pub struct Net { tap: Tap, avail_features: u64 , acked_features: u64 , queues: [Queue; NET_NUM_QUEUES], queue_evts: [EventFd; NET_NUM_QUEUES], irq_trigger: IrqTrigger, config_space: ConfigSpace, state: DeviceState, pub activate_evt: EventFd, } unsafe impl Send for Net {}impl VirtioDevice for Net { fn avail_features (&self ) -> u64 { self .avail_features } fn acked_features (&self ) -> u64 { self .acked_features } fn set_acked_features (&mut self , acked_features: u64 ) { self .acked_features = acked_features; } fn device_type (&self ) -> u32 { VIRTIO_TYPE_NET } fn queues (&self ) -> &[Queue] { self .queues.as_slice () } fn queues_mut (&mut self ) -> &mut [Queue] { self .queues.as_mut_slice () } fn queue_events (&self ) -> &[EventFd] { self .queue_evts.as_slice () } fn interrupt_trigger (&self ) -> &IrqTrigger { &self .irq_trigger } fn read_config (&self , offset: u32 , data: &mut [u8 ]) { if let Some (config_space_bytes) = self .config_space.as_slice ().get (offset as usize ..) { let len = config_space_bytes.len ().min (data.len ()); data[..len].copy_from_slice (&config_space_bytes[..len]); debug!("read config space {len}" ); } } fn write_config (&mut self , offset: u32 , data: &[u8 ]) { if let Some (config_space_bytes) = self .config_space.as_mut_slice ().get_mut (offset as usize ..) { let len = config_space_bytes.len ().min (data.len ()); config_space_bytes[..len].copy_from_slice (&data[..len]); debug!("write config space {len}" ); } } fn activate (&mut self , mem: GuestMemoryMmap) -> io::Result <()> { if self .has_feature (VIRTIO_RING_F_EVENT_IDX) { for queue in &mut self .queues { queue.noti_suppres = true ; } } self .activate_evt.write (1 )?; self .state = DeviceState::Activated { mem }; debug!("activate done" ); Ok (()) } fn is_activated (&self ) -> bool { self .state.is_activated () } }
MMIOTransport 在握手结束后会调用 activate 通知设备就绪,那么如何处理这个事件呢?这里的处理方式是将处理 tx、rx、tap 的 callback 注册到主线程的 epoll 上。这样,当事件发生时(tx/rx 就绪,或 tap 读/写就绪),就可以触发 Net 设备执行 relay 动作。
relay 实现起来并不困难,最简单的办法是持有一个 buffer,从一侧读取并写入到另一侧。但是,由于 Descriptor Chain 实际上等价于 [iovec],所以我们可以另外定义一个转换 trait 来将 Descriptor Chain 低成本地转换为 [iovec]。这样我们可以直接利用 readv/writev 并且避免额外的拷贝开销(这里设计 buffer 为传入 &mut Vec,预期调用方管理,以避免 Vec 的频繁分配开销):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 pub trait IntoIoVec { fn into_iovec (self , buffer: &mut Vec <libc::iovec>, write_only: bool ) -> io::Result <&[libc::iovec]>; } impl <M: Deref<Target = impl GuestMemory > + Copy > IntoIoVec for DescriptorChain <M> { fn into_iovec ( self , buffer: &mut Vec <libc::iovec>, write_only: bool , ) -> io::Result <&[libc::iovec]> { unsafe { buffer.set_len (0 ) }; let mut next_desc = Some (self ); while let Some (desc) = next_desc { if write_only && desc.is_write_only () || (!write_only && !desc.is_write_only ()) { buffer.push (libc::iovec { iov_base: desc .mem .get_slice (GuestAddress (desc.addr), desc.len as usize ) .map_err (|_| io::Error::new (io::ErrorKind::Other, "Failed to get slice" ))? .ptr_guard_mut () .as_ptr () as *mut _, iov_len: desc.len as _, }); } else { return Err (io::Error::new ( io::ErrorKind::Other, "Descriptor write_only bit not matches" , )); } next_desc = desc.next ().transpose ().map_err (|_| { io::Error::new (io::ErrorKind::Other, "Failed to get next descriptor" ) })?; } Ok (buffer.as_slice ()) } }
另一个问题是状态管理。tx 和 rx queue 可以近似认为是边缘触发(无论注册到 epoll 上的时候是ET/LT,只要 VIRTIO_F_EVENT_IDX 被协商,就是边缘触发效果,正常实现下需要消费到空才会得到下一次通知),那么这里需要考虑 tap fd 需要关注什么方向,边缘触发还是水平触发。通常,采用边缘触发并记录状态更高效。这里还有一个背景,就是 TUN/TAP 设备永远 writable(根据文档内核会在 buffer 满时静默丢弃,可以通过 ebpf 观测 SKB_DROP_REASON_FULL_RING 指标确认这点)。
这里 tx、rx、tap 都使用边缘触发,而拷贝只能在两侧都 ready 的时候进行,所以有三种实现方式:
不记录状态:通过读/写的返回值判定,此时可能会付出额外的代价,例如当 tap 不 readable 时,rx 的 ready 触发了读 queue 读 tap,此时就是一个无效操作;同理,当 rx 为空时,tap readable 触发了读 queue 写 tap,此时也是无效操作。
记录单侧状态(操作代价较高的那侧):显然,对 virtio queue 的读写代价并不高,tx 和 rx queue 的可读和可写对应了两个 Available Ring 的 pop 操作,其代价相比 TAP 的 syscall 可以忽略。我们记录 TAP 设备的 readable 状态,这样可以解决前一种方式中部分问题(记录 TAP 状态对于未协商 VIRTIO_F_EVENT_IDX 的情况更为重要):
不 readable 时对 tx queue 的 pop 和 unpop,以及一些结构转换开销
记录双侧状态(tx 和 rx 以及 TAP 的 read/write 共 4 个状态):这样的实现最高效。可以解决方式 2 中的:
tx avail_ring 无数据时的判定
rx avail_ring 无数据时的判定
分析完三种实现方式,考虑到对 avail_ring 的无数据的判定实际上比较 cheap(需要付出的代价是内存屏障和数字比较开销),我们按照方式 2 实现。
事件触发:
RX Ready:判定 TAP 是否 readable 并从 TAP 向 RX 循环拷贝数据
TX Ready:从 TX 向 TAP 循环拷贝数据
TAP Read Ready:从 TAP 向 RX 循环拷贝数据
这里将发送侧循环拷贝实现为 process_tx,将接收侧实现为 process_rx。之后还需要将这三个事件对应到各自的逻辑(例如由 EventFd 触发的事件需要先读一下 EventFd,由 TAP 可读触发的事件需要更新 readable 状态)以及这两个处理函数上,这块代码会在后续 EventLoop 实现后补充,这里仅实现两个共用的 process 函数。
在实际用于生产的 firecracker 和 cloud-hypervisor 中,这里还做了 rate limiter。在结合 rate limiter 后,这两个实现均相对较为复杂,也都有各自的问题。firecracker 存在读数据时拷贝问题,会先读到自己的 buffer 内再 copy 到 desc chain(虽然这种行为在小包场景有一定的合理性);cloud-hypervisor 有使用水平触发带来的频繁 epoll_ctl syscall 的问题,并且对于 TAP TX 的处理也有大量无效代码,因为 TUN/TAP 设备的 write 一定不会返回 WOULD_BLOCK(当 kernel ring buffer 满时会静默丢弃)。
后续我会尝试提交一些 PR 解决这些问题(PR List 见文末)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 impl Net { pub fn process_tx (&mut self ) -> io::Result <()> { let mem = self .state.unwrap (); let queue = &mut self .queues[TX_INDEX]; let mut try_notify = false ; loop { let desc = match queue.pop (mem) { Ok (Some (x)) => x, Ok (None ) => break , Err (_) => { error!("queue pop failed when process tx" ); continue ; } }; let desc_idx = desc.index; match self .tap.writev (desc) { Ok (_n) => { queue.push (mem, desc_idx, 0 ); try_notify = true ; } Err (e) => { queue.push (mem, desc_idx, 0 ); error!("tap writev failed {e}" ); try_notify = true ; } }; } if try_notify && queue.prepare_notify (mem) { self .irq_trigger.trigger (IrqType::Vring)?; } Ok (()) } pub fn process_rx (&mut self ) -> io::Result <()> { if !self .tap.readable { debug!("tap not readable when process rx" ); return Ok (()); } let mem = self .state.unwrap (); let queue = &mut self .queues[RX_INDEX]; let mut try_notify = false ; loop { let desc = match queue.pop (mem) { Ok (Some (x)) => x, Ok (None ) => break , Err (_) => { error!("queue pop failed when process rx" ); continue ; } }; let desc_idx = desc.index; match self .tap.readv (desc) { Ok (n) => { if let Err (e) = desc.write_at (VNET_HDR_NUM_BUFFERS_OFFSET, &u16 ::to_le_bytes (1 )) { error!("write vnet header num buffers failed: {e}" ); } queue.push (mem, desc_idx, n as u32 ); try_notify = true ; } Err (e) if e.kind () == io::ErrorKind::WouldBlock => { debug!("tap not readable when readv, mark readable false" ); self .tap.readable = false ; queue.undo_pop (); break ; } Err (e) => { error!("readv failed: {e:?}" ); queue.push (mem, desc_idx, 0 ); try_notify = true ; } }; } if try_notify && queue.prepare_notify (mem) { self .irq_trigger.trigger (IrqType::Vring)?; } Ok (()) } }
TAP 设备实现 TAP 设备用于提供二层网络。Linux 下创建一个 TAP 网卡很容易,只要打开 /dev/net/tun 并通过 ioctl 进行合理的配置即可。
与常规用法不同,由于我们直接中转带有 virtio net header 的数据包,所以需要在进出 TAP 设备时去除和添加相关包头。这个过程可以在用户态操作,也可以直接交给内核实现:配置 flag 时添加 IFF_VNET_HDR 并通过 ioctl 设置包头长度即可。
但需要注意的是,按照 virtio-net 的协议规范,在转发的过程中需要填充对应的数据。例如,device 必须设置 virtio_net_hdr 中的 num_buffers 字段(但是,我读了 QEMU 和 Firecracker 对应的代码,发现其在未开启 VIRTIO_NET_F_MRG_RXBUF 时不填充该字段,按照规范需要填充 1;所以我也看了一下 Kernel 的 driver 实现,其在未协商 VIRTIO_NET_F_MRG_RXBUF 时不会尝试读取该字段。虽然不填充并不符合标准,但是对于当前 virtio-net driver 实现来讲它是 work 的)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 pub struct Tap { file: File, buffer: Vec <libc::iovec>, pub readable: bool , pub writable: bool , } impl AsRawFd for Tap { fn as_raw_fd (&self ) -> std::os::unix::prelude::RawFd { self .file.as_raw_fd () } } impl Tap { pub fn new (name: &str ) -> io::Result <Self > { const DEVICE: &str = "/dev/net/tun\0" ; const FLAGS: i16 = (libc::IFF_TAP | libc::IFF_NO_PI | libc::IFF_VNET_HDR) as i16 ; const TUNSETIFF: libc::c_ulong = 0x4004_54ca ; let fd = unsafe { libc::open ( DEVICE.as_ptr () as *const _, libc::O_RDWR | libc::O_NONBLOCK | libc::O_CLOEXEC, ) }; if fd < 0 { return Err (io::Error::last_os_error ()); } let file = unsafe { File::from_raw_fd (fd) }; let mut cname = [0 ; IFNAMSIZ]; if name.as_bytes ().len () >= IFNAMSIZ { return Err (io::Error::new ( io::ErrorKind::InvalidInput, "interface name too long" , )); } cname[..name.as_bytes ().len ()].copy_from_slice (name.as_bytes ()); let mut ifr = ifreq { ifr_name: unsafe { transmute::<[u8 ; IFNAMSIZ], [libc::c_char; IFNAMSIZ]>(cname) }, ifr_ifru: unsafe { zeroed () }, }; ifr.ifr_ifru.ifru_flags = FLAGS; if unsafe { libc::ioctl (fd, TUNSETIFF, &ifr) } < 0 { return Err (io::Error::last_os_error ()); } Ok (Self { file, buffer: Vec ::new (), readable: false , writable: false , }) } pub fn set_vnet_hdr_size (&self , size: libc::c_int) -> io::Result <()> { const TUNSETVNETHDRSZ: libc::c_ulong = 0x4004_54d8 ; if unsafe { libc::ioctl (self .file.as_raw_fd (), TUNSETVNETHDRSZ, &size) } < 0 { return Err (io::Error::last_os_error ()); } Ok (()) } pub fn readv <B: IntoIoVec>(&mut self , data: B) -> io::Result <usize > { let iov = data.into_iovec (&mut self .buffer, true )?; let ret = unsafe { libc::readv (self .file.as_raw_fd (), iov.as_ptr (), iov.len () as i32 ) }; if ret == -1 { return Err (io::Error::last_os_error ()); } Ok (ret as usize ) } pub fn writev <B: IntoIoVec>(&mut self , data: B) -> io::Result <usize > { let iov = data.into_iovec (&mut self .buffer, false )?; let ret = unsafe { libc::writev (self .file.as_raw_fd (), iov.as_ptr (), iov.len () as i32 ) }; if ret == -1 { return Err (io::Error::last_os_error ()); } Ok (ret as usize ) } }
Segment Offload TAP 设备还可以实现地更高效:
通过添加 IFF_MULTI_QUEUE feature 支持多队列,并利用不同的线程处理不同的队列,这样可以最大化 CPU 多核利用率并提升其最大吞吐。是否支持该功能可以视目标场景决定,例如对于期望高密度部署的低单机 IO 需求实例,便没有必要支持。本系列文章中并无计划支持该特性。
将高级特性透传到 TAP 设备,例如 TSO、USO、UFO。此时需要在 device 支持的特性中 enable 这些位,并在成功协商对应位后开启 TAP 设备的对应特性。Cloudflare 的这篇 blog 中有一些 TSO/USO 在性能上的参考数据。
为了保证兼容性,参考 QEMU 的行为 ,我们需要在创建 TAP 时探测当前 kernel 下这些特性的可用性,并以此构建 device feature。
我们需要探测的 TAP features 以及其分别对应的 virtio feature:
TUN_F_CSUM - VIRTIO_NET_F_CSUM
TUN_F_TSO4 - VIRTIO_NET_F_GUEST_TSO4
TUN_F_TSO6 - VIRTIO_NET_F_GUEST_TSO6
TUN_F_TSO_ECN - VIRTIO_NET_F_GUEST_ECN
TUN_F_UFO - VIRTIO_NET_F_GUEST_UFO
TUN_F_USO4 - VIRTIO_NET_F_GUEST_USO4
TUN_F_USO6 - VIRTIO_NET_F_GUEST_USO6
注:virtio 文档 1.3 版本及后续版本,或 kernel header 中,可以找到对应定义。
VIRTIO 文档中有两类 feature,一类例如 VIRTIO_NET_F_CSUM,一类例如 VIRTIO_NET_F_GUEST_CSUM。
前者不带 GUEST,表示 Host 接收数据的特性。例如 VIRTIO_NET_F_CSUM 表示 Host 接受部分 checksum 的数据,那么若 Host 表明自己支持该 feature,则需要在必要时做校验;若未协商出该 feature,则 Guest 需要保证其给出的数据都是带有正确校验和的。所以,我们可以为其对应的 TAP 设备打开 TUN_F_CSUM flag,该 flag 表示 TAP 的使用者可以接受 unchecksummed packets(对应 iftun.h 中的注释:You can hand me unchecksummed packets.)。
后者带 GUEST,表示 GUEST 接收数据的特性。例如 VIRTIO_NET_F_GUEST_CSUM 表示 Guest/Driver 可以接受部分 checksum 的数据,其内部在需要时会做 checksum 校验。
要实现对分段卸载的支持,要做两方面的事情:
Guest → TAP 方向:Guest 需要发送更长的分段(这意味着 checksum 计算也要卸载到 Host 执行),需要支持协商 VIRTIO_NET_F_CSUM 和 VIRTIO_NET_F_HOST_{TSO4,TSO6,ECN,UFO,USO} (Device can receive);TAP 需要支持发送这种数据包,需要开启 TUN_F_CSUM 等 flag。
TAP → Guest 方向:Guest 需要接收更长的分段(这意味着对收到数据包的 checksum 计算要 Guest Driver 执行),需要支持协商 VIRTIO_NET_F_GUEST_CSUM 和 VIRTIO_NET_F_GUEST_{TSO4,TSO6,ECN,UFO,USO4,USO6} (Driver can receive);TAP 需要支持读出这种数据包,需要开启 TUN_F_TSO4 等 flag。
最终流程(以 TSO4 为例):
probe TAP 支持的 flag(TUN_F_TSO4);
将 flag 转换为 virtio features(VIRTIO_NET_F_GUEST_TSO4 | VIRTIO_NET_F_HOST_TSO4)。这是因为 TAP 支持 TSO4,所以我们可以收发 TSO4 的数据;
将协商后的 feature 转换回 TAP flag(VIRTIO_NET_F_GUEST_TSO4 → TUN_F_TSO4)并设置。这是因为开启 TUN_F_TSO4 则意味着可能接收到该格式的数据,由于我们直接将其透传给 Guest,所以 Guest 必须要支持才行,所以必须协商出 VIRTIO_NET_F_GUEST_TSO4 才能对 TAP 设置该 flag;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 #[derive(Debug, Clone, Copy)] pub struct TapOffload (libc::c_uint);impl TapOffload { const AVAIL_MAPPING: [(libc::c_uint, u64 ); 7 ] = [ (TUN_F_CSUM, VIRTIO_NET_F_GUEST_CSUM | VIRTIO_NET_F_CSUM), (TUN_F_TSO4, VIRTIO_NET_F_GUEST_TSO4 | VIRTIO_NET_F_HOST_TSO4), (TUN_F_TSO6, VIRTIO_NET_F_GUEST_TSO6 | VIRTIO_NET_F_HOST_TSO6), ( TUN_F_TSO_ECN, VIRTIO_NET_F_GUEST_ECN | VIRTIO_NET_F_HOST_ECN, ), (TUN_F_UFO, VIRTIO_NET_F_GUEST_UFO | VIRTIO_NET_F_HOST_UFO), (TUN_F_USO4, VIRTIO_NET_F_GUEST_USO4 | VIRTIO_NET_F_HOST_USO), (TUN_F_USO6, VIRTIO_NET_F_GUEST_USO6 | VIRTIO_NET_F_HOST_USO), ]; const FEAT_MAPPING: [(u64 , libc::c_uint); 7 ] = [ (VIRTIO_NET_F_CSUM, TUN_F_CSUM), (VIRTIO_NET_F_GUEST_TSO4, TUN_F_TSO4), (VIRTIO_NET_F_GUEST_TSO6, TUN_F_TSO6), (VIRTIO_NET_F_GUEST_ECN, TUN_F_TSO_ECN), (VIRTIO_NET_F_GUEST_UFO, TUN_F_UFO), (VIRTIO_NET_F_GUEST_USO4, TUN_F_USO4), (VIRTIO_NET_F_GUEST_USO6, TUN_F_USO6), ]; pub fn virtio_features (&self ) -> u64 { if self .0 & TUN_F_CSUM == 0 { return 0 ; } let mut features = 0 ; for (tun, virtio) in Self ::AVAIL_MAPPING.iter () { if self .0 & tun != 0 { features |= *virtio; } } features } pub fn from_virtio_features (features: u64 ) -> Self { if features & VIRTIO_NET_F_CSUM == 0 { return Self (0 ); } let mut tun = 0 ; for (virtio, t) in Self ::FEAT_MAPPING.iter () { if features & virtio != 0 { tun |= *t; } } Self (tun) } pub fn into_inner (self ) -> libc::c_uint { self .0 } } impl Tap { pub fn probe (&self ) -> TapOffload { let mut features : libc::c_uint = 0 ; const PROBE_LIST: &[libc::c_uint] = &[ 0 , TUN_F_TSO4, TUN_F_TSO6, TUN_F_TSO_ECN, TUN_F_UFO, TUN_F_USO4, TUN_F_USO6, ]; for p in PROBE_LIST { let probe = *p | TUN_F_CSUM; if self .set_offload (probe).is_ok () { features |= probe; } } TapOffload (features) } pub fn set_offload (&self , offload: libc::c_uint) -> io::Result <()> { const TUNSETOFFLOAD: libc::c_ulong = 0x4004_54d0 ; if unsafe { libc::ioctl (self .file.as_raw_fd (), TUNSETOFFLOAD, offload) } < 0 { return Err (io::Error::last_os_error ()); } Ok (()) } }
周边组件实现 Bus 由于我们可能需要挂载多个设备,所以需要一个组件来:
注册设备到地址段
根据地址段分发读写请求
考虑到当前存在 PIO 和 MMIO 两种地址空间和对应设备,我们可以定义这么一种 Bus:
1 2 3 4 5 6 7 8 pub struct Bus <A, D> { devices: Vec <BusDevice<A, D>>, } struct BusDevice <A, D> { range: Range<A>, device: Arc<Mutex<D>>, }
这里使用 Arc<Mutex<D>> 的原因是设备需要被 Bus 和事件 callback 共享;Bus 内使用 Vec 管理是因为这样可以利用二分搜索快速查找地址对应的设备。
实现插入和查找:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 impl <A, D> Bus<A, D> { pub const fn new () -> Self { Self { devices: Vec ::new (), } } } impl <A: PartialOrd <A>, D> Bus<A, D> { pub fn insert (&mut self , range: Range<A>, device: Arc<Mutex<D>>) -> Result <(), ()> { if range.is_empty () { return Err (()); } let insert_idx = self .devices .partition_point (|d| d.range.start < range.start); if insert_idx < self .devices.len () && range.end > self .devices[insert_idx].range.start { return Err (()); } self .devices.insert (insert_idx, BusDevice { range, device }); Ok (()) } pub fn get (&self , addr: &A) -> Option <(&A, &Arc<Mutex<D>>)> { self .devices .binary_search_by (|d| { if d.range.contains (addr) { std::cmp::Ordering::Equal } else if &d.range.start > addr { std::cmp::Ordering::Greater } else { std::cmp::Ordering::Less } }) .ok () .map (|idx| (&self .devices[idx].range.start, &self .devices[idx].device)) } }
当我们需要分发读写请求时,设备并不关心自己的绝对地址,或者说拿到绝对地址也无法理解其含义,其关心的是地址的 offset,所以我们需要计算并约束 offset:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 pub trait DeviceIO { type Offset ; fn read (&mut self , offset: Self ::Offset, data: &mut [u8 ]); fn write (&mut self , offset: Self ::Offset, data: &[u8 ]); } impl <A, D, O> Bus<A, D>where A: PartialOrd <A> + Sub<A, Output = O> + Copy + std::fmt::LowerHex, D: DeviceIO<Offset = O>, { #[inline] pub fn read (&mut self , addr: A, data: &mut [u8 ]) -> bool { if let Some ((base, device)) = self .get (&addr) { let mut device = device.lock ().unwrap (); let offset = addr - *base; device.read (offset, data); true } else { false } } #[inline] pub fn write (&mut self , addr: A, data: &[u8 ]) -> bool { if let Some ((base, device)) = self .get (&addr) { let mut device = device.lock ().unwrap (); let offset = addr - *base; device.write (offset, data); true } else { false } } }
这样一来,我们就可以基于 Bus 给出 PIOBus 和 MMIOBus 的 alias:
1 2 3 4 5 6 7 8 9 10 11 12 pub type PIOBus = Bus<u16 , PIODevice>;pub type MMIOBus = Bus<u64 , MMIODevice>;#[non_exhaustive] pub enum PIODevice { Serial (SerialDevice), } #[non_exhaustive] pub enum MMIODevice { MMIOTransport (MMIOTransport), }
我们可以为这两种 Bus 实现更便捷的插入方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 impl PIOBus { #[inline] pub fn insert_serial (&mut self , address: u16 , serial: Arc<Mutex<PIODevice>>) -> Result <(), ()> { const SERIAL_PORT_SIZE: u16 = 0x8 ; self .insert (address..address + SERIAL_PORT_SIZE, serial) } } impl MMIOBus { #[inline] pub fn insert_virtio ( &mut self , address: u64 , device: Arc<Mutex<dyn VirtioDevice>>, mem: GuestMemoryMmap, ) -> Result <(), ()> { const MMIO_SIZE: u64 = 0x1000 ; let device = MMIODevice::MMIOTransport (MMIOTransport::new (device, mem)); self .insert (address..address + MMIO_SIZE, Arc::new (Mutex::new (device))) } }
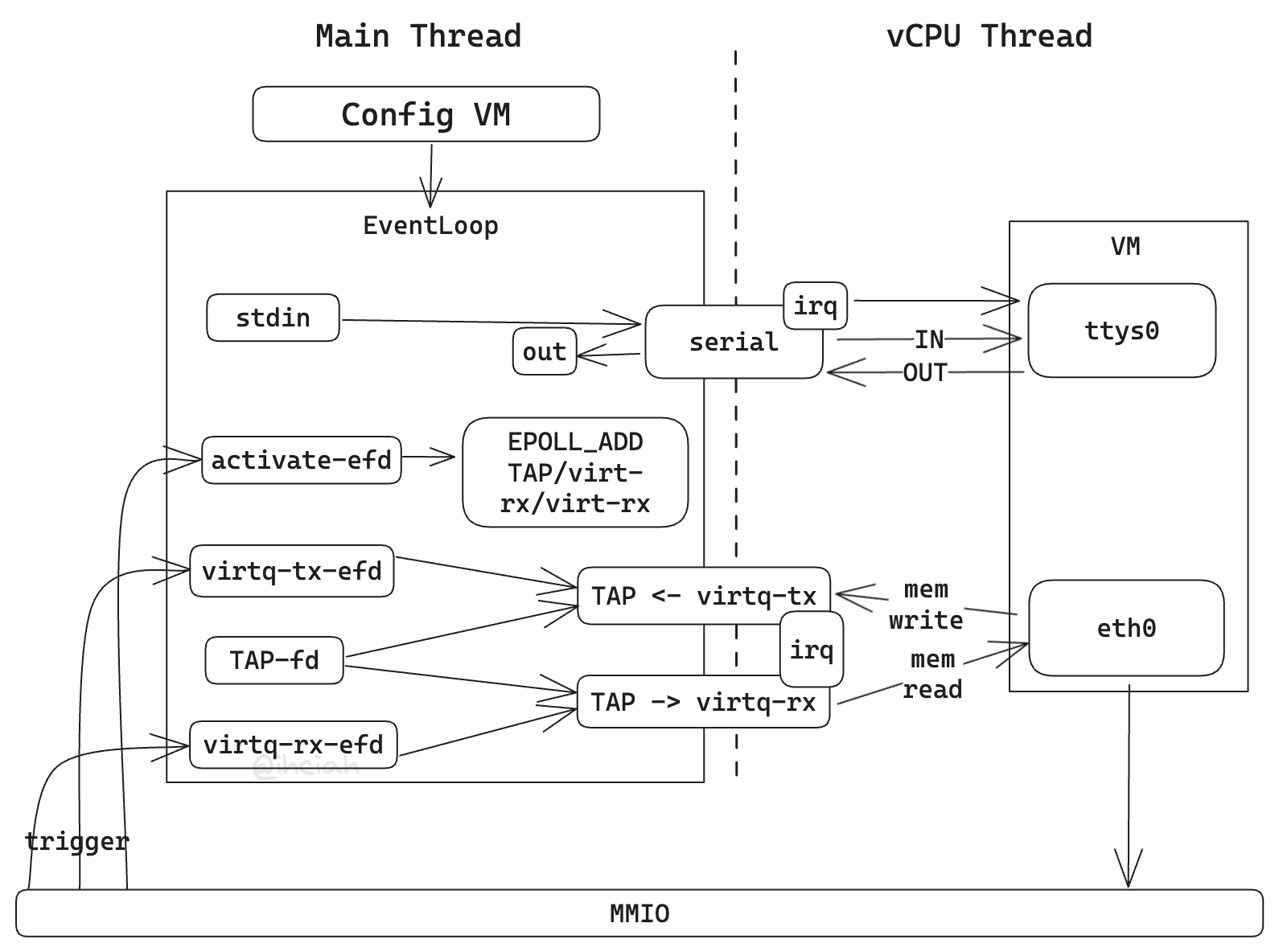
EventLoop 先前我们对事件的处理逻辑是这种形式表达的:
1 2 3 4 5 6 7 8 9 10 11 loop { let events = epoll_wait (); for event in events { match event.user_data { 1 => { ... }, 2 => { ... }, _ => { ... }, } } }
这种形式的缺陷在于所有逻辑都要混在一起,且无法动态注册删除,在事件较多时代码不可维护。
我们现在新增了设备,需要处理多种事件,所以有必要实现一个更好用的 EventLoop 来解决这个问题(我之前写过的一个 Rust 异步运行时某种意义上讲也是一种 EventLoop,可以参考 Rust Runtime 设计与实现系列文章 )。
实现 EventLoop 的核心在于如何描述 Callback:我们暂且将其定为 T。基于这个可以实现事件注册和基础结构定义。实现上使用 Slab 存储 T,并将 slab id 用作 user_data。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 use slab::Slab;use vmm_sys_util::epoll::{ControlOperation, Epoll, EpollEvent};pub use vmm_sys_util::epoll::EventSet;pub const DEFAULT_EPOLL_EVENT_CAP: usize = 128 ;pub struct EventLoop <T = Arc<dyn EventHandler>> { epoll: Epoll, events: Vec <EpollEvent>, callbacks: Slab<T>, } impl <T> EventLoop<T> { pub fn new () -> io::Result <Self > { Self ::with_capacity (DEFAULT_EPOLL_EVENT_CAP) } pub fn with_capacity (size: usize ) -> io::Result <Self > { let epoll = Epoll::new ()?; Ok (Self { epoll, events: RefCell::new (vec! [unsafe { zeroed () }; size]), callbacks: Slab::new (), }) } pub fn register (&mut self , fd: &impl AsRawFd , event: EventSet, callback: T) -> io::Result <()> { let fd = fd.as_raw_fd (); let user_data = self .callbacks.insert (callback); self .epoll .ctl ( ControlOperation::Add, fd, EpollEvent::new (event, user_data as u64 ), ) .map_err (|e| { let _ = self .callbacks.remove (user_data); e })?; Ok (()) } }
EventLoop 还需要提供等待并处理事件的函数,涉及事件处理逻辑,此时就需要约束 T 了。
由于我们可以拿到 &mut T ,所以最直观的我们可以约束:
1 2 3 pub trait EventHandlerMut { fn handle_event_mut (&mut self , events: EventSet); }
这时当我们想对 Arc/Rc 和 Mutex/RefCell 的任意组合实现的时候,问题就来了:
通过 Arc 只能拿到内层的只读引用,无法调用其 handle_event_mut 方法!
解决这个问题有两种方式,一种是手动展开组合,为 Arc<Mutex<T>> 和 Arc<RefCell<T>> 等实现该 trait 转发至 T 的实现;另一种是再引入一个只读版本的 trait:
1 2 3 pub trait EventHandler { fn handle_event (&self , events: EventSet); }
这时对于 Arc<T>,当 T 实现 EventHandler 时,Arc<T> 便可基于此实现 EventHandlerMut;对于 Mutex<T>,当 T 实现 EventHandlerMut 时,Mutex<T> 可以实现 EventHandler。这样的效果是,若 T:EventHandlerMut 则 Arc<Mutex<T>>:EventHandlerMut,达成我们的目标。
我们可以写出其 tick 方法:
1 2 3 4 5 6 7 8 9 impl <T: EventHandlerMut> EventLoop<T> { pub fn tick (&mut self , timeout: i32 ) -> io::Result <usize > { let n = self .epoll.wait (timeout, &mut self .events[..])?; for event in self .events.iter ().take (n) { self .callbacks[event.data () as usize ].handle_event_mut (event.event_set ()); } Ok (n) } }
另外,对于前面提到的,设备 activate 后需要动态注册的需求,支持起来会遇到一些困难:
设备 activate 是在 eventloop 的 handler 里执行的,此时 handler 会 hold 住 &mut callbacks
而该 handler 又期望能够注册新的 eventset 和 callback 到 EventLoop,此时需要写入 callbacks
此时我们可以引入一个预注册解决这个问题(另外也可以将 handler 做成共享所有权结构,每次处理时先 clone 获得其所有权以解除对 callbacks 的引用,但这样会引入一定性能开销):
pre_register:该操作只将 callback 加入 callbacks,得到 slab id,需要持有 &mut EventLoop
associate:将 slab id 关联到 epoll(即执行 epoll_ctl EPOLL_ADD)
第一个阶段在启动时做,第二个阶段可以在任何时候执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 pub struct EventLoop <T = Arc<dyn EventHandler>> { epoll: Rc<Epoll>, events: Vec <EpollEvent>, callbacks: Slab<T>, } #[derive(Debug)] pub struct PreRegister { epoll: Rc<Epoll>, user_data: usize , } impl <T> EventLoop<T> { pub fn pre_register (&mut self , callback: T) -> PreRegister { let user_data = self .callbacks.insert (callback); PreRegister { epoll: self .epoll.clone (), user_data, } } } impl PreRegister { pub fn associate (&self , fd: &impl AsRawFd , event: EventSet) -> io::Result <()> { let fd = fd.as_raw_fd (); self .epoll.ctl ( ControlOperation::Add, fd, EpollEvent::new (event, self .user_data as u64 ), )?; Ok (()) } }
一个 EventLoop 对应一个 thread,其可以承载所有 IO,这样可以做到更低的资源占用和更高的部署密度,但极限 IO 并不高,因为只有一个或少量线程执行 IO;也可以为每一个设备启动单独线程运行 EventLoop(甚至可以打开设备的 MultiQueue feature 并为每个 Queue 启动独立线程),这样可以做到较高的极限性能,但资源占用较多。
这里我的代码使用了第一种形式,将所有 IO 在主线程上模拟。
组装 我们已经实现完了所有必要的组件,现在需要在 main 里将其组装起来了。
整理一下我们现在已经实现的组件:
VM 配置,Kernel 和 initrd 加载:这部分是在本节之前就完成的
serial 实现:这部分也是本节之前就完成的,需要挂载到 PIOBus 上
EventLoop:用于更优雅地管理事件和执行对应 Callback
Bus:包含 MMIOBus 和 PIOBus,用于在 VM_EXIT 后分发处理事件
TAP 组件和 Virtio Queue 实现:Net 组件内部使用
Net 组件:持有 TAP 并负责在 virtio queue 和 TAP 间中转数据
MMIOTransport:用于包装 Net 组件并挂载到 MMIOBus 中,以此暴露 MMIO 形式的设备操作接口
那么在 main 中我们可以按照下面的顺序初始化:
log 初始化,提供一定的观测能力
创建 KVM fd、VM fd,并创建 irq_chip, pit,并初始化内存
创建 vCPU
加载 initrd 和 kernel
初始化寄存器和页表并完成模式切换
写入 boot cmdline 并配置 Linux 启动参数
创建 PIOBus 并插入 Serial 设备
创建 MMIOBus 并插入 MMIO 设备
创建 EventLoop,并注册 stdin、virtio-net-activate,以及 exit_evt 三个 fd
启动新线程模拟 vCPU,并在退出后通知 exit_evt
主线程启动 EventLoop,并在得到 exit_evt 通知后停止循环并退出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 fn main () { let file_appender = tracing_appender::rolling::daily ("/tmp" , "mini-vmm.log" ); let (non_blocking, _guard) = tracing_appender::non_blocking (file_appender); tracing_subscriber::registry () .with (tracing_subscriber::fmt::layer ().with_writer (non_blocking)) .with ( tracing_subscriber::EnvFilter::builder () .with_default_directive (LevelFilter::DEBUG.into ()) .from_env_lossy (), ) .init (); tracing::info!("mini-vmm started" ); let kvm = Kvm::new ().expect ("open kvm device failed" ); let vm = kvm.create_vm ().expect ("create vm failed" ); vm.create_irq_chip ().unwrap (); let pit_config = kvm_pit_config { flags: KVM_PIT_SPEAKER_DUMMY, ..Default ::default () }; vm.create_pit2 (pit_config).unwrap (); let guest_addr = GuestAddress (0x0 ); let guest_mem = GuestMemoryMmap::<()>::from_ranges (&[(guest_addr, MEMORY_SIZE)]).unwrap (); let host_addr = guest_mem.get_host_address (guest_addr).unwrap (); let mem_region = kvm_userspace_memory_region { slot: 0 , guest_phys_addr: 0 , memory_size: MEMORY_SIZE as u64 , userspace_addr: host_addr as u64 , flags: KVM_MEM_LOG_DIRTY_PAGES, }; unsafe { vm.set_user_memory_region (mem_region) .expect ("set user memory region failed" ) }; vm.set_tss_address (KVM_TSS_ADDRESS).expect ("set tss failed" ); let mut vcpu = vm.create_vcpu (0 ).expect ("create vcpu failed" ); let kvm_cpuid = kvm.get_supported_cpuid (KVM_MAX_CPUID_ENTRIES).unwrap (); vcpu.set_cpuid2 (&kvm_cpuid).unwrap (); let mut kernel_file = File::open (KERNEL_PATH).expect ("open kernel file failed" ); let kernel_entry = Elf::load ( &guest_mem, None , &mut kernel_file, Some (GuestAddress (HIMEM_START)), ) .unwrap () .kernel_load; let initrd_content = std::fs::read (INITRD_PATH).expect ("read initrd file failed" ); let first_region = guest_mem.find_region (GuestAddress::new (0 )).unwrap (); assert! ( initrd_content.len () <= first_region.size (), "too big initrd" ); let initrd_addr = GuestAddress ((first_region.size () - initrd_content.len ()) as u64 & !(4096 - 1 )); guest_mem .read_volatile_from ( initrd_addr, &mut Cursor::new (&initrd_content), initrd_content.len (), ) .unwrap (); let mut regs = vcpu.get_regs ().unwrap (); regs.rip = kernel_entry.raw_value (); regs.rsp = BOOT_STACK_POINTER; regs.rbp = BOOT_STACK_POINTER; regs.rsi = ZERO_PAGE_START; regs.rflags = 2 ; vcpu.set_regs (®s).unwrap (); let mut sregs = vcpu.get_sregs ().unwrap (); const CODE_SEG: kvm_segment = seg_with_st (1 , 0b1011 ); const DATA_SEG: kvm_segment = seg_with_st (2 , 0b0011 ); sregs.cs = CODE_SEG; sregs.ds = DATA_SEG; sregs.es = DATA_SEG; sregs.fs = DATA_SEG; sregs.gs = DATA_SEG; sregs.ss = DATA_SEG; let gdt_table : [u64 ; 3 ] = [ 0 , to_gdt_entry (&CODE_SEG), to_gdt_entry (&DATA_SEG), ]; let boot_gdt_addr = GuestAddress (BOOT_GDT_OFFSET); for (index, entry) in gdt_table.iter ().enumerate () { let addr = guest_mem .checked_offset (boot_gdt_addr, index * std::mem::size_of::<u64 >()) .unwrap (); guest_mem.write_obj (*entry, addr).unwrap (); } sregs.gdt.base = BOOT_GDT_OFFSET; sregs.gdt.limit = std::mem::size_of_val (&gdt_table) as u16 - 1 ; sregs.cr0 |= X86_CR0_PE; let boot_pml4_addr = GuestAddress (0xa000 ); let boot_pdpte_addr = GuestAddress (0xb000 ); let boot_pde_addr = GuestAddress (0xc000 ); guest_mem .write_slice ( &(boot_pdpte_addr.raw_value () | 0b11 ).to_le_bytes (), boot_pml4_addr, ) .unwrap (); guest_mem .write_slice ( &(boot_pde_addr.raw_value () | 0b11 ).to_le_bytes (), boot_pdpte_addr, ) .unwrap (); for i in 0 ..512 { guest_mem .write_slice ( &((i << 21 ) | 0b10000011u64 ).to_le_bytes (), boot_pde_addr.unchecked_add (i * 8 ), ) .unwrap (); } sregs.cr3 = boot_pml4_addr.raw_value (); sregs.cr4 |= X86_CR4_PAE; sregs.cr0 |= X86_CR0_PG; sregs.efer |= EFER_LMA | EFER_LME; vcpu.set_sregs (&sregs).unwrap (); let mut params = boot_params::default (); const KERNEL_TYPE_OF_LOADER: u8 = 0xff ; const KERNEL_BOOT_FLAG_MAGIC_NUMBER: u16 = 0xaa55 ; const KERNEL_HDR_MAGIC_NUMBER: u32 = 0x5372_6448 ; const KERNEL_MIN_ALIGNMENT_BYTES: u32 = 0x0100_0000 ; params.hdr.type_of_loader = KERNEL_TYPE_OF_LOADER; params.hdr.boot_flag = KERNEL_BOOT_FLAG_MAGIC_NUMBER; params.hdr.header = KERNEL_HDR_MAGIC_NUMBER; params.hdr.cmd_line_ptr = BOOT_CMD_START as u32 ; params.hdr.cmdline_size = 1 + BOOT_CMD.len () as u32 ; params.hdr.kernel_alignment = KERNEL_MIN_ALIGNMENT_BYTES; params.hdr.ramdisk_image = initrd_addr.raw_value () as u32 ; params.hdr.ramdisk_size = initrd_content.len () as u32 ; const E820_RAM: u32 = 1 ; const EBDA_START: u64 = 0x9fc00 ; const FIRST_ADDR_PAST_32BITS: u64 = 1 << 32 ; const MEM_32BIT_GAP_SIZE: u64 = 768 << 20 ; const MMIO_MEM_START: u64 = FIRST_ADDR_PAST_32BITS - MEM_32BIT_GAP_SIZE; add_e820_entry (&mut params, 0 , EBDA_START, E820_RAM); let last_addr = guest_mem.last_addr (); let first_addr_past_32bits = GuestAddress (FIRST_ADDR_PAST_32BITS); let end_32bit_gap_start = GuestAddress (MMIO_MEM_START); let himem_start = GuestAddress (HIMEM_START); if last_addr < end_32bit_gap_start { add_e820_entry ( &mut params, himem_start.raw_value (), last_addr.unchecked_offset_from (himem_start) + 1 , E820_RAM, ); } else { add_e820_entry ( &mut params, himem_start.raw_value (), end_32bit_gap_start.unchecked_offset_from (himem_start), E820_RAM, ); if last_addr > first_addr_past_32bits { add_e820_entry ( &mut params, first_addr_past_32bits.raw_value (), last_addr.unchecked_offset_from (first_addr_past_32bits) + 1 , E820_RAM, ); } } let mut boot_cmdline = Cmdline::new (0x10000 ).unwrap (); boot_cmdline.insert_str (BOOT_CMD).unwrap (); load_cmdline (&guest_mem, GuestAddress (BOOT_CMD_START), &boot_cmdline).unwrap (); LinuxBootConfigurator::write_bootparams ( &BootParams::new (¶ms, GuestAddress (ZERO_PAGE_START)), &guest_mem, ) .unwrap (); const SERIAL_PORT: [u16 ; 4 ] = [0x3f8 , 0x2f8 , 0x3e8 , 0x2e8 ]; const COM_1_3_GSI: u32 = 4 ; const COM_2_4_GSI: u32 = 3 ; let mut pio_bus = PIOBus::new (); let stdio_serial_inner = new_serial (SerialOutOpt::StdOut); let serial_2_4_inner = new_serial (SerialOutOpt::Sink); let com_1_3_trigger = stdio_serial_inner.interrupt_evt ().try_clone ().unwrap (); vm.register_irqfd (&com_1_3_trigger, COM_1_3_GSI).unwrap (); vm.register_irqfd (serial_2_4_inner.interrupt_evt ().as_ref (), COM_2_4_GSI) .unwrap (); let serial_3 = new_serial_with_event (com_1_3_trigger, SerialOutOpt::Sink); let stdio_serial = Arc::new (Mutex::new (bus::PIODevice::Serial (stdio_serial_inner))); let com_3_serial = Arc::new (Mutex::new (bus::PIODevice::Serial (serial_3))); let com_2_4_serial = Arc::new (Mutex::new (bus::PIODevice::Serial (serial_2_4_inner))); pio_bus .insert_serial (SERIAL_PORT[0 ], stdio_serial.clone ()) .unwrap (); pio_bus .insert_serial (SERIAL_PORT[1 ], com_2_4_serial.clone ()) .unwrap (); pio_bus.insert_serial (SERIAL_PORT[2 ], com_3_serial).unwrap (); pio_bus .insert_serial (SERIAL_PORT[3 ], com_2_4_serial) .unwrap (); let mut mmio_bus = MMIOBus::new (); let virtio_net = virtio::net::Net::new ("tap0" , Some (GUEST_MAC)).unwrap (); let virtio_net_activate_evt = virtio_net.activate_evt.as_raw_fd (); vm.register_irqfd (&virtio_net.interrupt_trigger ().irq_evt, 5 ) .unwrap (); for (q_sel, evt) in virtio_net.queue_events ().iter ().enumerate () { let addr = IoEventAddress::Mmio (QUEUE_NOTIFY_OFFSET + MMIO_MEM_START); vm.register_ioevent (evt, &addr, q_sel as u32 ).unwrap (); } let virtio_net = Arc::new (Mutex::new (virtio_net)); mmio_bus .insert_virtio (MMIO_MEM_START, virtio_net.clone (), guest_mem.clone ()) .unwrap (); let stdin_fd = { let stdin = std::io::stdin ().lock (); stdin.set_raw_mode ().expect ("set terminal raw mode failed" ); stdin .set_non_block (true ) .expect ("set terminal non block failed" ); stdin.as_raw_fd () }; let mut poller : EventLoop = EventLoop::new ().unwrap (); poller .register (&stdin_fd, EventSet::IN, stdio_serial) .unwrap (); let cb = Arc::new (EventLoopRegisterHandler::new (virtio_net, &mut poller)); poller .register (&virtio_net_activate_evt, EventSet::IN, cb) .unwrap (); let exit_evt = EventWrapper::new (); let vcpu_exit_evt = exit_evt.try_clone ().unwrap (); std::thread::spawn (move || { loop { match vcpu.run () { Ok (run) => match run { VcpuExit::IoIn (addr, data) => { pio_bus.read (addr, data); } VcpuExit::IoOut (addr, data) => { pio_bus.write (addr, data); } VcpuExit::MmioRead (addr, data) => { mmio_bus.read (addr, data); } VcpuExit::MmioWrite (addr, data) => { mmio_bus.write (addr, data); } VcpuExit::Hlt => { info!("KVM_EXIT_HLT" ); break ; } VcpuExit::Shutdown => { info!("KVM_EXIT_SHUTDOWN" ); break ; } r => { info!("KVM_EXIT: {:?}" , r); } }, Err (e) => { error!("KVM Run error: {:?}" , e); break ; } } } vcpu_exit_evt.trigger ().unwrap (); }); let exit = Rc::new (Cell::new (false )); let exit_trigger = exit.clone (); poller .register ( &exit_evt, EventSet::IN, Arc::new (Mutex::new (FnHandler (move |_| { exit_trigger.set (true ); }))), ) .unwrap (); loop { poller.tick (-1 ).unwrap (); if exit.get () { info!("vcpu stopped, main loop exit" ); break ; } } }
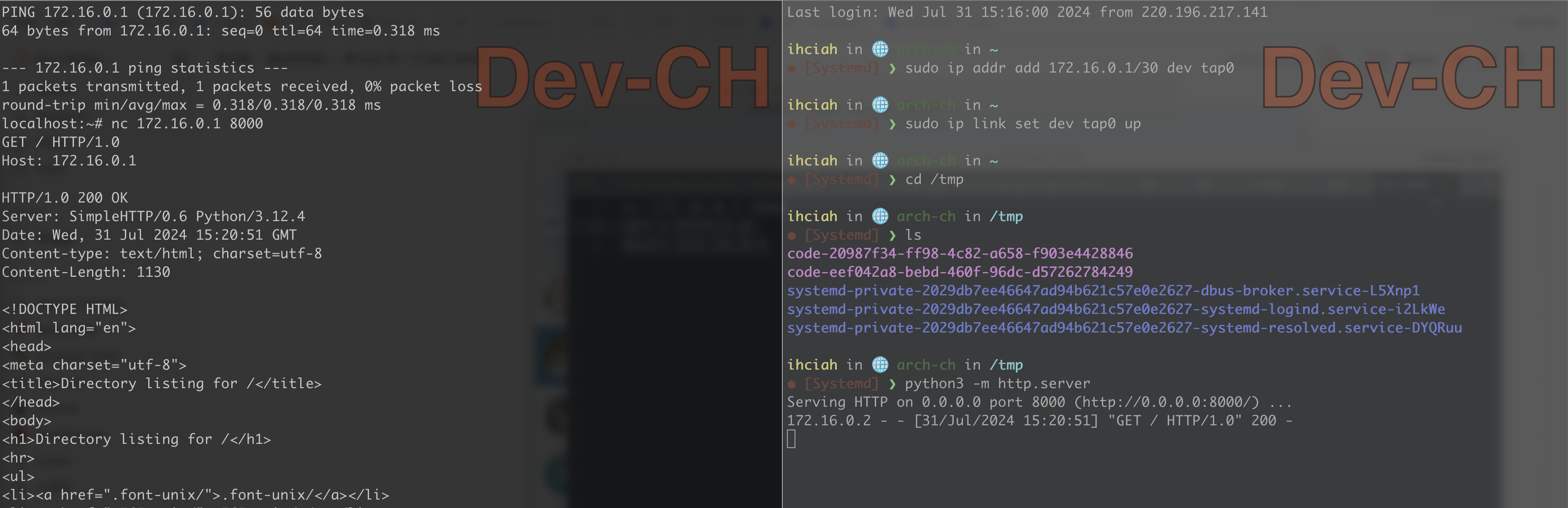
运行 启动 Guest 后,配置 Host TAP 并在 Guest 验证可以正常访问 Host:
在 Host 开启内核转发,并配置 nat 规则;在 Guest 配置默认路由后,Guest 即可连通外部网络:
简单配置 /etc/resolv.conf 后,可以通过下载大文件验证其正确工作:
完整代码可以在这里找到:https://github.com/ihciah/mini-vmm
优化 firecracker/cloud-hypervisor 在本实验中,我参考了部分 firecracker、cloud-hypervisor 和 QEMU 的实现,在一些方面借鉴了他们的优秀的设计,在另一些方面我也提出了我认为更优的新的实现方式。我会挑选一些值得改进的点为它们(指前两个项目)提交 PR。PR List: