This article also has an English version.
本文将介绍我写的一个 Rust 调用 Golang FFI 框架的设计与实现,从设计和实现者的角度设计多种方案并给出选择和原因,以及介绍一些实现细节。
项目已开源于 Github:https://github.com/ihciah/rust2go。
相比 Golang,Rust 程序没有 GC,并且有更强的编译检查,基于 LLVM 获得了最强的编译优化,所以拥有更好的性能和安全性。
在字节跳动内部,为了推动成本优化,我从零造了服务发现、metrics、log、动态配置等多个业务必要的 Rust SDK,发起并参与了 Rust RPC 框架开发,以及提供了编译与运行镜像、crates 内部源和公网镜像(rsproxy.cn)等。在这些基建之上,多个核心业务迁移至 Rust 并取得了较大的性能收益:CPU 占用降低 30% 以上,部分延迟敏感业务 P99 显著降低。但是,这些业务很多是不需要积极维护的,例如代理、缓存类,有较复杂且积极迭代的业务逻辑的服务则较难迁移 Rust。
理论上我们可以将所有 Golang 程序使用 Rust 重写以获得更好的性能,但是实际操作中仍存在较大困难:一是重写全部 Golang 依赖组件不一定现实,二是一口气完成全部重写较为困难。如果提供一种从 Rust 高效调用 Golang 的手段,能够让业务可以循序渐进地完成 Rust 重构,那么这两个问题都可以解决。
本文涉及内容较多,整体叙述脉络:首先讨论整体方案的选型并给出一个极简 PoC;之后从这个极简 PoC 入手,扩展并细化该方案以支持必要的特性;最后会从框架实现角度介绍一些值得讨论的实现细节。
我在 2024 年的 RustChinaConf 上分享了这个议题,如果你感兴趣,欢迎浏览视频回放或 PPT(视频链接,PPT 链接)。
注意,这篇文章并不是一个面向用户的使用文档。
方案选型与简单 PoC

Rust 调用 Golang 可以实现为多种方式:
- 借助跨进程通信方式,如 TCP/UDS,通过序列化和 RPC 交互数据。这种方式实现简单,且不会出现潜在的内存安全问题;但缺点是太慢了:它需要依赖 Socket 传输数据,并且数据需要经过序列化和反序列化。它需要 4 次内存拷贝和 2 次内存分配:序列化(一次拷贝,一次分配)、Socket 发送(一次应用到内核的拷贝)、Socket 接收(一次内核到应用的拷贝)和反序列化(一次拷贝,一次分配;这里我将多个字段视作一次)。
- 基于跨线程通信。如果我们有效利用多语言在同一进程这个事实,那么就可以省掉一些不必要的拷贝和上下文切换开销。需要传输的数据可以直接存放于内存中,只需要在预先约定了数据表示后,将数据地址通知对端即可。然而,我们仍需要内核提供一些通知手段,如 eventfd 或 UDS,而这些仍然会产生较大开销。
- 基于 FFI(Foreign Function Interface)。借助 FFI 我们可以直接在当前线程发起跨语言函数执行。但是不同语言 ABI 不同(Rust 甚至没有稳定的 ABI)我们必须使用统一约定的 ABI 才能完成正常调用——这个约定就是 C。在 Golang 中我们可以使用 CGO 暴露 C 接口函数,并在 Rust 中利用 extern “C” 声明函数,之后即可直接调用。这种方式性能最好,但是需要对齐函数调用和内存表示,以及做一些额外的工作来支持异步任务。
简易 FFI 例子
任何复杂的工作都可以从一个简单的 PoC 入手。我们可以在 Golang 中通过如下代码暴露 C 接口的函数:
1 | package main |
之后在 Rust 中声明并使用:
1 | extern "C" { |
最后在 Rust 侧利用 build.rs 生成 golang 静态库并辅助 rustc 链接:
1 | use std::{path::PathBuf, env, process::Command}; |
在这个 PoC 中,执行 go build -buildmode=c-archive 会生成 go 静态库 libgo.a,同时在 $OUT_DIR 生成 libgo.h。之后通过 cargo:rustc-link-search=native= 将 $OUT_DIR 加入搜索路径(所以 extern "C" 时不需要额外指定路径),最后利用 cargo:rustc-link-lib=static=go 将 libgo.a 链接进来。
Dive a little deep
到此为止我们已经可以从 Rust 调用 Golang 的简单函数(无参数,无返回值)了,但这是远远不够的。要满足实际需求,就要支持更多能力,需要考虑这些能力对应的实现方案。
参数传递
前面的 POC 中,函数没有参数和返回值。但是真实环境中这种 case 很少。
要传递参数,我们就需要考虑其表示形式。一个众所周知的事实是,不同语言中的相似结构很难能够直接被互相理解。我们可能不得不付出一些开销来将这些表示统一为一种“标准表示”。
参数表示
参数表示我们可以选用两种方案:序列化和引用表示。
序列化通常被用于跨机通信,会将数据编码到连续内存中,并使用固定的 endian。常见的文本序列化协议例如 json、xml;二进制序列化协议例如 thrift、protobuf、capn proto 等。
但对于 FFI,传递参数的双方在同一进程中:
- 因为可以访问同一块内存,数据并不需要串行发送,所以数据表示没必要连续
- 在保证生命周期正确的情况下,没有必要拷贝
- 因为跑在同机所以其 arch 一定相同,所以更不需要 endian 转换

虽然序列化的方案实现起来较为简单,用到的组件都是现成的,但考虑到上述几条原因,出于性能考虑这里我决定使用引用表示来传递参数和返回值。所谓引用表示,指传递的是包含指向非连续内存指针的数据。例如传递 String 时我们实际传递的是指针和长度;而对于 u16 会直接传递 u16(会使用 target machine endian)。
采用引用表示时,我们需要访问对端内存,所以需要额外关注其内存表示。
内存表示
内存表示上,我们只能使用 C 内存布局的结构来表示数据,否则双边无法互相理解。
例如当我们要传递 Vec<u8> 时,虽然其内部就是指针和长度,但我们不能直接传递该结构,因为 Rust 编译器可能会对该结构插入 padding 或将 field 重排序。所以对这个需求,我们要将 pointer 和 length 放置于一个 struct 内传递,并添加 #[repr(C)] 以控制结构的内存布局。
对于 String 也是类似的:我将 String 表示为 StringRef,其的定义如下:
1 |
|
对于用户定义的结构,也可以定义类似的引用结构,例如:
1 |
|
在实现时,这种引用结构可以利用 build.rs 或 derive 宏生成(在本文实现部分会详细介绍)。
返回值传递
对于参数,我们需要从所有权类型获得其引用类型;对于返回值,这个过程是反着的,我们需要解引用。Golang 侧会返回包含指针的数据,需要在 Rust 侧从指针转换回所有权类型数据(需要考虑是否拷贝)。
涉及指针解引用和拷贝,这里就引入了两个新问题:
- 如何保证指针引用的合法性?
- 要不要拷贝数据,以及如何分配内存?
下面我们讨论几种方案,看看是否可以满足上述两个问题。

方案 1:FFI 返回值直接返回指针
在 Golang 中,执行完函数后,所有无引用的数据都会在 GC 时释放,那么 Golang 返回给 Rust 的数据中的指针就一定会变成悬垂指针,这时访问其指向内容可能就会发生非预期后果。所以对应前面的第一个问题,这种方式没办法保证指针引用的合法性,更不用谈第二个问题了。
方案 2:FFI 无返回值,返回值内存由 Rust 侧提前分配,并在调用时传递指针,Go 函数在结束前将返回值主动拷贝到该指针对应内存
这个方案看起来可以解决第一个问题,因为 Golang 持有的数据被拷贝至 Rust 侧。
但这个方案事实上仍旧会面临内存归属问题:当拷贝一个 String 时,必须是深拷贝,而在 Golang 中分配的内存仍旧归属 Golang 管理,无法移交 Rust 侧。
一个缓解的方式是在 CGO 中手动申请内存并拷贝数据,此时可以将含指针(可以保证指针合法性)的返回值表示写入 Rust 侧的预分配的 slot;并额外暴露接口允许 Rust 在使用完毕后释放对应内存。但这种缓解会带来更大的复杂度,多余的内存释放操作的 FFI(正比于和对象个数)会带来较大 overhead,Rust 侧需要使用特殊的 Allocator 构造 String 和 Vec(影响易用性)或付出一次拷贝开销(影响性能)。这种缓解方式甚至性能上比序列化方案还要差。
方案 3:利用 FFI 传递返回值
如果我们利用额外的一次 FFI 传递返回值呢?这样我们可以在 hold 住 Golang 侧内存不被释放的情况下切换到 Rust 环境,这样就可以既保证 Golang 侧指针的合法性,又能正常分配内存。
利用 FFI 传递返回值

我们可以在 Rust 调用 Golang 的线程中再次调用 Rust。由于 Rust 侧拿到返回值后我们无法控制其 lifetime(上层逻辑甚至可能会将其放入一个全局结构),所以在 Rust 侧被 FFI 调用时的拷贝无法避免;Rust 侧在被调用后执行拷贝,此时内存是 Rust 分配的,在其 Drop 时可以正常释放。
现在我们只需要考虑如何执行 callback FFI 了。
当前这个思路看起来要求 Golang 可以直接调用 Rust,那么就要求 Rust 侧能够暴露为 lib 并被 golang 链接。这既会给编译带来麻烦,并且十分令人困惑:为什么我只从 Rust 调用 Go,却需要 Rust 暴露为 library。
但既然是函数的 callback,我们完全可以将指针传递过去,理论上就应当能够完成调用——函数调用无非是按照约定将返回值和参数压栈或设置到寄存器后 call 函数地址。而暴露为 lib 的效果也仅仅是将对应函数名和地址写入到导出表,这和我们在 Rust 主动发起调用时传递指针效果应当是一致的。
Golang 跳转函数指针
Golang 调用 Rust 仍旧面临 ABI 不一致问题。
要解决该问题,一个方案是利用一段汇编强行对齐 ABI(在尝试该方案时找到了一个很有意思的相关实现:Hooking Go from Rust)。但是考虑到 Rust ABI 本身不稳定,以及后续支持异步时,发起 FFI 的是 goroutine 需要解决扩栈问题,我没有选择这种方案。
事实上我用的方案更简单:直接使用 CGO,Rust 侧暴露 callback 为 C ABI,并在 CGO 中定义函数,强转为 C 函数指针并调用。
为什么使用 CGO?在 goroutine 中执行的 go 函数都会在进入时做栈空间检查,如果不满足自身需求则会在运行时扩栈;而执行 FFI 时则无法插入这个检查并扩栈的行为。使用 CGO 发起 FFI,Golang 会切换到 G0 栈以避免 FFI 时栈空间可能不够用的问题。
1 | package main |
这段 POC 插入 C wrapper 代码完成指针转换,并在 Go 代码中利用 CGO 跳转调用。
内存安全性

我们当前考虑两种类型的结构:所有权类型和引用类型。
- 当 Rust 侧发起 FFI 调用时,Rust 上下文持有参数所有权类型,并传递引用类型到 Golang,此时 Rust 所在线程被占用,不可能释放所有权类型数据,故此时是安全的。
- Golang 函数在阻塞执行时可以安全地使用传入的参数指针。
- Golang 函数执行完毕,通过另外的一次主动 FFI 向 Rust 发送返回值引用,此时 Golang 侧所有权类型可以保证不被 GC。
- Rust 侧在被 FFI 时拿到 Golang 发来的返回值指针,此时需要立刻拷贝数据到 Rust 内存。
- Callback FFI 完全结束,此时 Rust 侧已完成返回值数据拷贝,故 Golang 可以释放返回值。
- Rust 侧调用完全结束,此时 Golang 不可继续持有含引用的参数(对于未手动拷贝的参数,需要谨慎使用可能 leak lifetime 的函数)。
异步支持
Rust 异步系统可以参考我之前的文章。
网络编程中我们很难避开异步,被调用的 Golang 代码往往也是如此。此时如果我们用上述方式支持 Rust 调用 Golang,就会发现在 Golang 侧执行网络 IO 期间,Rust 所在线程被 Golang 调用阻塞住了。这会导致 worker 线程利用率大幅降低,对外表现是请求延迟飙升,负载能力大幅下降。
解决这个问题最简单的支持方式是利用 Rust Runtime 通常都会提供的 spawn blocking。Spawn blocking 设计上是将较重的或包含阻塞的逻辑发送至独立的线程池执行并异步等待,等待期间 worker 线程仍旧可以处理其他任务。
但这种方式只能应付较低频的同步任务,当同步任务耗时较长且数量较多时,众多线程便会带来巨大的线程切换开销。当同步任务处于热路径时,此时本质上异步 Runtime 已经约等于 Java 风格的线程池了。
Rust 与 Go 的协程对比
Rust 中使用无栈协程,任务本身在陷入等待时需要主动返回,并由事件源负责通知 Runtime 再次调度该任务。
但 Golang 使用有栈协程,它隐藏了 netpoll 细节,并通过支持抢占来允许用户发起阻塞 syscall。
这是两种完全不同的模型。
更高效的异步支持
Rust 任务在 Rust 侧 Runtime 执行,Golang 任务在 Golang 侧执行,两者在底层上都是异步非阻塞 IO。我们没有必要去干涉过多的任务切换,更没有必要幻想将 Golang 任务丢到 Rust Runtime 执行。
事实上我们只需要能够非阻塞地执行 Golang 函数,并在其执行完毕时得到通知即可。这要 hack Go runtime 吗?Maybe it works。但有一个更简单的办法:go task()。谜底就在谜面上,最常见的 go 关键字就是非阻塞执行 Golang 函数的秘诀。
我们只需要将用户提供的函数包装一下:
1 | func wrapper() { |
然后在 callback 实现内 wake 相应 waker 即可。
但是这里需要额外注意,Rust 允许任务被误唤醒,且 Golang 执行 callback 是在 Go 线程做的,所以我们必须保证 callback 执行和 Rust 侧任务唤醒时读返回值这两个行为是并发安全的。
为了能够在 callback 中唤醒任务,在 Rust 侧发起 FFI 时除了需要提供 callback pointer、参数列表、返回值 slot pointer 外,还需要提供 waker。之后 Go 对 callback pointer 指向函数发起 FFI,传入返回值 slot pointer 和 waker。例如:
1 | /* |
在 Rust 侧只需要提供一层 Future,拿到 waker 后发起 FFI,callback 函数内执行从 WakerRef 结构构造 Waker 后执行 wake:
1 |
|
复杂类型支持
前文中,我将结构分为所有权结构和引用结构。
- 所有权结构可以直接转换为引用结构,例如
String -> StringRef{ptr, len}、Vec<u8> -> ListRef{ptr, len} - 引用结构可以拷贝出所有权结构,
StringRef{ptr, len}->String
但这并不一定成立。例如,对于 Vec<String> 就无法做类似转换。因为对外层 Vec 取指针后得到的是指向 String 的指针,Golang 无法理解 String,仍需要将 String 转换为 {ptr, len} 构成的 StringRef 才行。要构造指向多个 StringRef 的指针,就需要分配空间存储这些中间结构。
我的第一版设计是额外定义一种中间类型(暂且称之为 Shadow 类型),存储中间结果,之后引用类型实际上同时依赖中间类型与所有权类型,使用时 Ownership -> Shadow -> Ref。
但这种设计会导致 struct 定义生成过于复杂(例如,Vec<Vec<Vec<u8>>> 需要依赖多个中间结构字段),而且中间类型会带来多次分配开销,所以最终没有选用。
回到问题本身,既然我们需要存储中间结构,那么能否使用单个连续内存表示呢?事实上是可以的,而且这种方案会将整个结构转换时的内存分配开销降低至一次。定义转换 trait 类似(实际实现中与此不同,应用了更多类型计算和常量优化):
1 | pub trait ToRef { |
在递归转换时,如果子结构需要写入中间存储,则其会自行写入,并返回可能包含引用中间存储的指针结构。最终返回的最上层结构即需要 FFI 发送的数据。
框架组件与实现
至此,我们基本已经讨论清楚所有关键问题的解法,已经可以根据需求手动实现一个 Rust 调用 Golang 的 wrapper 了。
但是我的目标是提供一个通用且易用的框架,让用户能够开箱即用,避开前面这么多复杂的问题,所以有必要提供通用的基础组件实现,和代码生成器。
描述调用约定
用户需要提供 FFI 的函数定义和相关结构定义。通常我们会使用某种 IDL 来描述它,例如 uniffi 定义了 UDL 来描述这个调用约定。
但是使用 IDL 也会给用户带来一定学习成本,还需要开发对应的 parser 和周边生态(例如 IDE 插件)。
这里我认为,既然本项目明确是 Rust 调 Go,而 Rust 的 trait 含义与调用接口基本一致,所以决定直接使用 Rust 语法(但限定仅可使用部分语法)作为 IDL。这么做用户没有额外学习成本,实现上也可以直接使用 syn、quote 等处理 Rust 代码的库,并且这份 IDL 可以同时作为普通代码被 Rust 项目使用。
用户可以定义 struct 和 trait,trait 中支持同步函数和异步函数(异步函数使用已稳定的 async-fn-in-traits 特性描述)。
例如,一个可被接受的接口约定可以是这样:
1 | pub struct DemoUser { |
代码生成方式
根据我们前面的问题分析,可以梳理出几种代码:
Golang 中的 所有权结构定义、引用结构定义和 export ffi 函数
首先 Golang 代码全部都需要能够手动生成,因为这部分代码可能会被拷贝至独立的 Go 仓库,这样该 Go Project 就可以独立开发编译,不需要依赖 Rust 环境。如果需要保证其版本一致性,可以在 Rust 项目的 build.rs 里调用相同生成器,再次生成并覆盖 go 源码文件。
在本实现中,C 结构定义(引用结构定义)是通过 cbindgen 生成的。首先 parse Rust 文件,并完成 Ref 结构生成,之后利用 cbindgen 将 Ref 结构生成为对应的 C 代码,之后贴入 Golang 代码的
import "C"之前。其余代码都需要 Rust 侧手动 format 模板。Rust 所有权结构定义、引用结构定义和 export callback ffi 函数
所有权结构定义已经由用户提供,不需要重定义。引用结构定义和 callback ffi 需要通过代码生成,这部分可以通过 derive 宏或手动解析并构造 TokenStream 写入文件。
在本实现中,引用结构和 callback ffi 由 derive 宏生成。这部分工作事实上与前面提到的通过代码生成 Ref 结构共用相同逻辑。
Rust Trait 定义、转换 Trait 定义
Trait 定义已经由用户提供,不需要重定义。转换 Trait 作为通用定义,不受用户影响,可以定义在公共库中。
Rust Trait 实现、转换 Trait 实现
在本实现中,Rust FFI Trait 和转换均实现通过宏实现。
通过宏实现代码生成要优于通过 build.rs,这种做法耦合度更低,编译效率也更高,对 IDE 也更友好。需要额外注意的是,由于需要链接 Golang,而 Golang 中我们引入了一份 C 结构定义,所以实际上会生成两份引用结构定义,这里直接 transmute 解决重复定义问题。

转换 trait 定义与实现
转换 trait 用于在所有权类型和引用类型之间互相转换。
ToRef
根据前面分析的结论,部分所有权结构在转换到引用结构时需要依赖中间存储。
由于中间结构内部写入的数据是指针,其会指向这段 buffer 自身,所以它必须一次分配足够的空间,不能够中途扩容。所以显然我们需要两个接口,一个接口用于计算空间占用,一个接口用于递归转换并写入数据。
我们可以讨论以下几个典型例子:
u8:这类数据任何时候都不需要占用中间存储。Vec<u8>:当这类数据处于最外层时,不需要占用中间存储;当其外层还有结构时就需要占用。Vec<Vec<u8>>:这类数据一定会占用中间存储。
根据这个讨论,这里我将数据分为三种类型:
- Primitive:基础类型,如 u8、u16、char,这种类型数据可以随意 Copy;空间计算时直接返回当前结构的 size 即可;转换为引用时返回自身。
- SimpleWrapper:对 Primitive 类型数据的单层引用,如
Vec<u8>、String、Vec<u16>、Map<u8, u16>;空间计算时返回指针和长度所占用内存大小;转换为引用时返回指针和长度。 - Complex:包含对 SimpleWrapper 类型数据引用的类型,如
Vec<Vec<u8>>,Vec<String>,Vec<Map<u8, u16>>;空间计算时需要计算自身大小并递归;转换为引用时需要递归转换并返回当前层转换结果。
这三种类型会决定我们要不要进行递归的空间占用计算和转换,利用这个可以避开对于最内层结构的递归。所以可以定义如下所有权转引用类型 trait:
1 | pub trait ToRef { |
此时我们可以为 Vec<T> 实现转换:
1 | impl<T: ToRef> ToRef for Vec<T> { |
当转换 Complex 类型时,需要先预留其 children 所需的 buffer 空间,并依次在完成 child 的转换后写入至预留位置。下图是一个转换的例子:
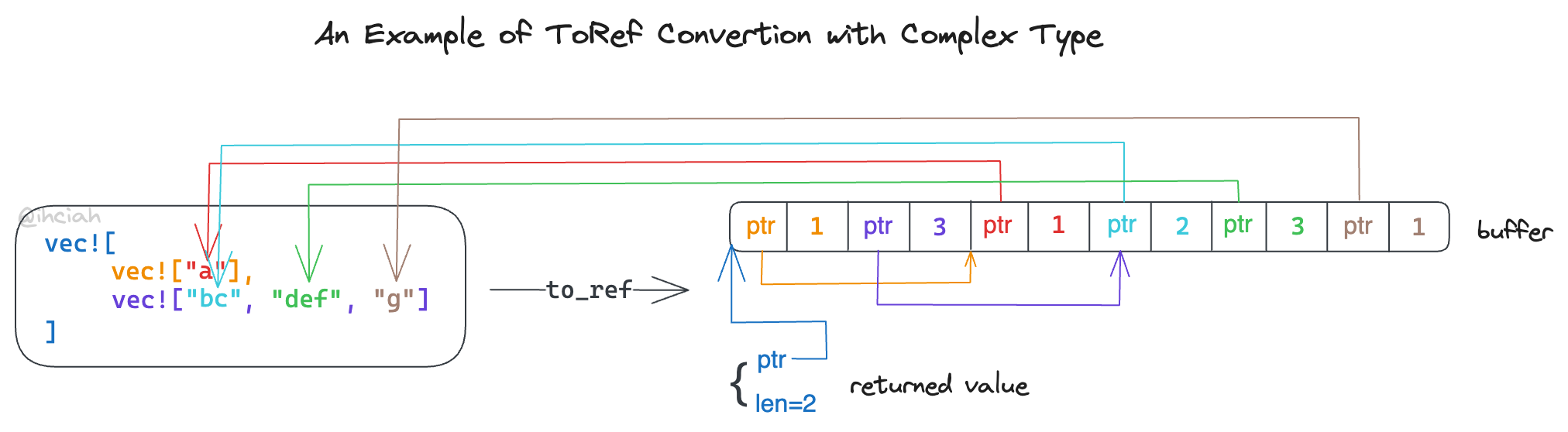
当然,Golang 侧也需要实现这个逻辑,但由于缺少健全的泛型支持(例如 Golang 不支持 impl<T> Trait for T 语义的泛型),这部分就不得不手动构造多层函数来做了。
FromRef
Rust 侧,从引用结构构建所有权结构的 trait 可以很直观地定义为:
1 | pub trait FromRef { |
对于复杂类型,可以有较为简单的实现,例如:
1 | impl<T: FromRef> FromRef for Vec<T> { |
Golang 侧也需要实现类似逻辑。可以定义一些辅助泛型函数来简化代码生成:
1 | func newSlice[T any](_param_ref C.ListRef) []T { |
对于如下的复杂 List,利用上述辅助泛型函数可以生成简单的转换实现:
1 | type DemoComplicatedRequest struct { |
异步调用时的内存安全性
Drop Safe
不同于同步调用会占用 Rust 侧线程,其可以保证引用到的数据不会被析构;异步调用时 Go FFI 函数立刻返回,并将在用户逻辑后台执行结束后再执行 callback FFI:这时如何保证内存安全呢?如果用户提前 Drop Future(这应当是安全的),如何避免 Golang 此时访问错误的内存?
这个问题其实与实现基于 io_uring 的 Rust Runtime 时面临的本质上是相同的难题(可以参考我写的 Rust Runtime 设计与实现-设计篇 Part1)。简单概括就是:如何保证在将指针提交到对端后,直到接到对端发回的完成通知前,指针对应数据的生命周期合法性。
在 Monoio 中我参考 tokio-uring 的做法,取得了相关 buffer 的所有权,并在提交到 kernel 前将 buffer 所有权转移至堆上并 leak,之后将指针存储于全局结构;在收到 kernel 返回后再从指针构造回并释放。
在本 case 中如果要保证内存安全也不得不采用类似的办法,来避免 Future 提前 drop 后 Golang 访问错误内存地址的问题。这里可能出现问题的一个是参数可能被释放,另一个是 Ret Slot 可能被释放(同步实现中,Ret Slot 放在栈上即可;异步实现中我们必须放在堆上)。
Ret Slot Lifetime
当 Rust 侧 Drop Future 后,我期望 Ret Slot 不被释放:Ret Slot 的释放时机应当是 Golang 侧完成写入且 Rust 侧完成读取或 Drop 时。为此,我设计了一个 Atomic 结构存储返回值(完整实现)。
1 |
|
State 是一个原子状态,其封装了 CAS 操作;SlotInner 持有状态和数据,封装了读写行为;SlotReader 和 SlotWriter 提供读写能力,并在 Drop 时有条件地(当 Reader 和 Writer 都 Drop 后)释放 SlotInner。
基于这个原子 Slot,可以保证:
- 在 Future Drop 后,Golang 侧依旧可以向 Slot 合法地写入数据。
- 在 Future 被误唤醒后,不会与 Golang 侧发起的写入逻辑产生竞争
参数 Drop Safe
对于传入所有权的参数,我们可以参考 Ret Slot 的做法存起来。由于其 lifetime 刚好与 Slot 一致,为了减少堆分配次数,这里直接将参数存入 Slot:
1 | struct SlotInner<T, A = ()> { |
例如上述 A 可能实际对应类型 (arg1, arg2, arg3)。
但是,如果参数中包含引用类型,我们仍旧无法保证 Future drop safe。
我定义了一个 #[drop_safe] 属性,如果函数包含这个属性,那么其参数必须是带有所有权的类型,否则会抛出错误。为了允许用户在执行完 call 后能够拿回参数所有权,又额外定义了一个 #[drop_safe_ret] 属性,这个属性在功能上类似 #[drop_safe],不同之处是其会影响返回值,返回值会变成类似 (Ret, (ARG1, ARG2, ARG3))。
而对于不带有这两个属性的异步函数,在生成代码时我会额外为其加上 unsafe 标记以告知用户必须保证 Future 在返回 Ready 前不被 drop。
在本节我介绍了实现角度如何描述调用约定、使用什么方式生成代码、以及如何生成引用结构并实现所有权结构与引用结构的转换,最后介绍了保证异步调用时内存安全的一些设计。
最终,使用本项目可以完成高效的(理论上这是最高效的方案)Rust 调用 Golang,并支持异步调用。未来本项目也计划支持 Go 主动调用 Rust。
更好的性能
Go FFI 和其他 native 语言的 FFI 不同,当其他语言调用 Golang 时,由于 Go 代码运行需要 Runtime,所以并非直接在调用方的线程上执行,而是 dispatch 到 Go 自行管理的 thread 上执行。前面的方案依赖 CGO 提供相关的 dispatch 实现。
使用 CGO 会导致 Golang 侧向 Rust 侧调用时切换到 G0 栈,而 Golang 在被调用时也需要跨线程的 dispatch。考虑到这些 cost,抛弃 CGO 探索其他更高性能的跨线程通信方式可能可以进一步提升性能(CGO 在 1.21 版本以前的实现性能不佳,1.21 版本有较大的优化)。
比较简单的方案是利用 TCP、UDS 等常见方式完成通信,发送和接收调用信息。但考虑到实际 Go 与 Rust 运行在同一个进程,共享同一块地址空间,所以更进一步的做法是利用共享内存和某种通知机制完成通信,潜在地减少跨线程通信次数。
这里我实现了一套基于共享内存的机制来替代 CGO,通知机制基于 EventFd/Unix Socket。
Memory Ring
Memory Ring 是本功能的核心部分。这部分我做成了独立的库,如有类似需求欢迎使用(包含 Rust 和 Go 实现,其中 Rust 部分支持 tokio/monoio):https://github.com/ihciah/rust2go/tree/master/mem-ring。
该 Ring 包含共享内存的读写、状态位读写,以及跨线程通知机制实现,以应对 ring 为空或已满的情况。
一个 Ring 设计上仅可被两侧同时使用,一侧只读,一侧只写(双向读写需要两个 Ring)。它的结构包含:
- buffer 的指针和长度,长度对应
T的个数 - head 和 tail index,该 index 使用 u64 存储,单调递增预期用不完
- working 标记和 stuck 标记
- working 和 unstuck 通知用 fd
在读取数据时:
- 需要先将 working 位置 1,之后开始持续消费。
- 每轮消费读 tail 并计算剩余长度,读出数据后更新 head;并且需要检查 stuck 位,若为 1 则需要通知 unstuck_fd。
- 当消费到空时,先执行一个短时间等待(例如
yield_now,或 golang 中的runtime.Gosched),之后继续读取 tail 判定长度,若非空,则继续上一步的常规消费逻辑。 - 若上一步在短时间等待后仍旧没有新数据,此时需要将 working 标记置为 0。
- 因为可能在置 0 的瞬间又有新的数据产生,所以仍需再次读取 tail 判定长度,若非空,则 working 置 1 并继续常规消费逻辑。
- 若上一步结果仍为空,则需要陷入等待,等待 working_fd 通知。
在写入数据时:
- 读取长度,若 ring 已满,则 stuck 标记置 1,并将数据加入 Pending 队列,写入完成。
- ring 未满则写入 ring 并更新 tail。
- 判定 working 位是否为 1,若为 1 则写入完成。
- 若 working 位为 0,则需要唤醒对端:working 位置 1 并通过 working_fd notify 对端消费。
此外,我们还需要一个后台 task 负责将 Penging 队列中的任务写入 Ring):
- 从 Pending 队列取任务,并尝试写入 queue,写入成功则继续取任务并写入。
- 若 queue 已满,则放回任务并中断循环。
- 若 Pending 队列已取完,则也中断循环。
- 循环退出后,检查 working 标记,若未 working,则通过 working_fd notify 对端消费。
- 判定 Pending 队列是否为空,非空则表示无法完成全部搬运工作,则继续打开 stuck 标记。
- 判定 queue 是否已满,未满则跳至步骤 1。
- 若 queue 仍旧已满,则等待 unstuck_fd 通知。
将这些逻辑分别以 Rust 和 Golang 实现,这样我们就完成了基础 Ring 的构建,并且它支持在 ring 为空或满的状态下利用 EventFd/Unix Socket 通知 peer。其中,working flag 设计显著地降低了跨线程通知的次数,在 benchmark 中可以观察到 batch 比例约为 150:1。
调用约定表示
使用两个 Ring,我们就已经构建了高效的双向通信机制。那么如何基于这两个 Ring 表示调用以及返回值呢?
让我们考虑无返回值的调用,由于调用需要传递指针,而对应内存的释放仍需要一次回包才可以确定。所以,无返回值的调用实际对应两次通信。
同理,有返回值的调用在传递返回值时也需要关心其生命周期,所以可以利用 4 次通信完成;良好的设计下可以优化为 3 次。
这里我设计了一个通用的 Payload 结构:
1 |
|
参数由 ptr 表示,多个参数时参数按顺序存储在对应内存;函数名由 call_id 表示;为了区分不同的请求,还有一个 user_data 唯一标记请求;
最后,对于有返回值的调用,利用 next_user_data 来合并对参数的释放通知和返回值,做到基于 3 次交互完成一次函数调用。
临时变量存储
当我们将指针发送给 peer 后,指针对应的对象是不能立刻释放的,必须等到函数调用结束,收到对端的释放通知才行。
此时我们需要一个地方存储这个结构。一个存储方式是利用 Box 将其存储在堆上并 leak,user_data 填充为 Box 的指针。
但这种方式需要额外内存分配,由于存储和释放非常频繁,我们可以考虑将这些数据存储在预先分配好的空槽里。
这里我选择的方式是使用 Slab 存储(由 tokio 团队维护的 crate),可以 O(1) 复杂度操作,并且内存是紧密排布的,利用率较高。
在 Golang 侧,我自己实现了一个带有分段锁的 Slab 版本,也能达到较好的性能。
把这些组装在一起
为了兼容原有的基于 CGO 的实现,我这里修改宏,新增定义了一个 #[mem],对于添加该属性的函数,生成基于共享内存的实现,并修改 r2g 过程宏,允许用户指定 queue size。例如:
1 |
|
在使用姿势上与 CGO 版本无任何差异。最终正确的到响应:
1 | ========== Start oneway demo ========== |
在 benchmark 场景下,使用 Go 1.18,共享内存模式相比基于 CGO 在多种参数下均有正向优化,最多优化了 20.01%。